From 0 to 10K Webhooks: Scaling Your First Implementation
A practical guide for startups on how to scale webhooks from your first implementation to handling 10,000+ events per hour. Learn what breaks at each growth phase and how to fix it before your customers notice.
From 0 to 10K Webhooks: Scaling Your First Implementation
Your MVP works. Then you land an enterprise customer or hit Hacker News—and everything breaks.
Scaling webhooks is predictable. The same problems break systems at the same volume thresholds. This guide maps that journey from first webhook to 10,000/hour, explaining what breaks at each phase and how to fix it before customers complain.
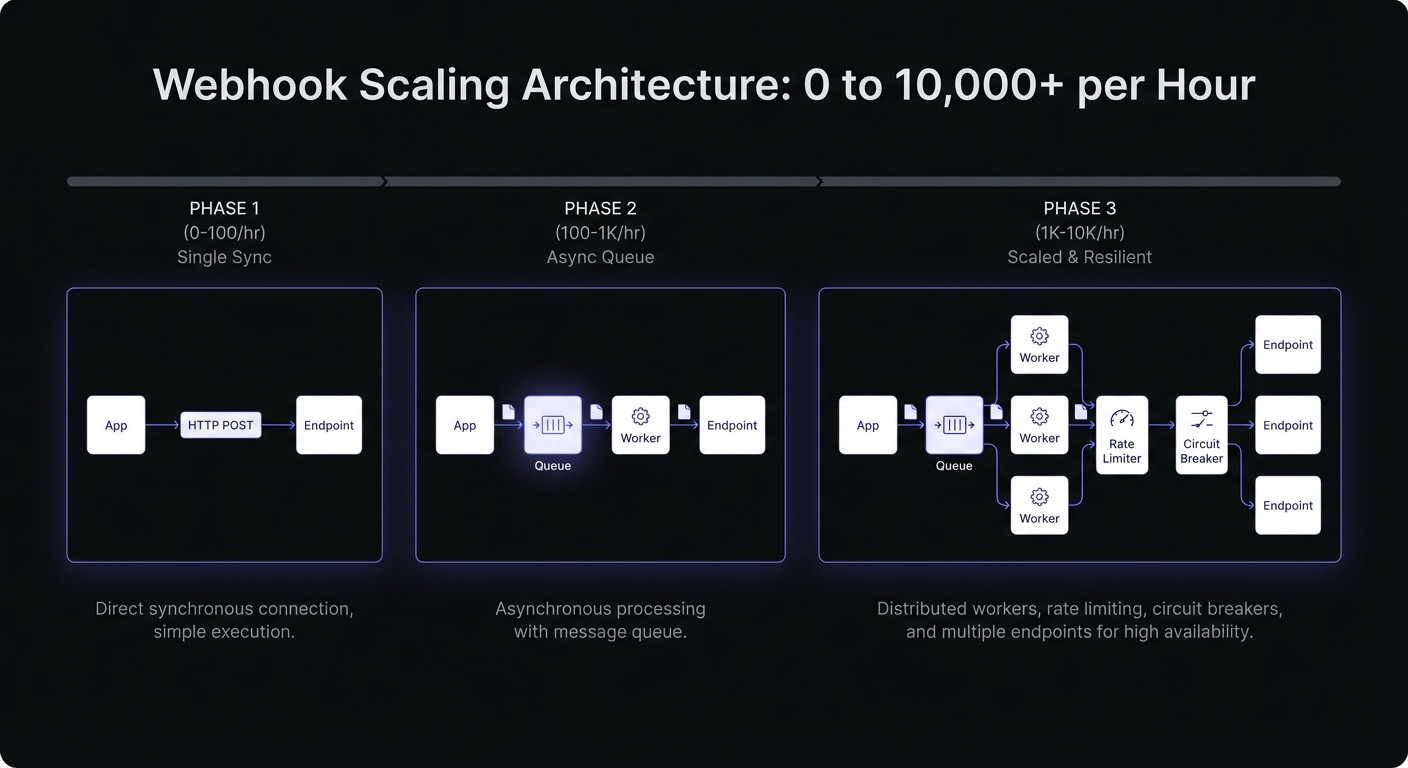
Phase 1: 0-100 Webhooks/Hour
Simplicity wins. Handful of customers, goal is shipping features.
Starting Architecture
Most teams use synchronous delivery: event occurs, HTTP POST, wait for response:
async function sendWebhook(endpoint, payload) {
try {
const response = await fetch(endpoint.url, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(payload),
timeout: 30000
});
await logDelivery(endpoint, payload, response.status);
} catch (error) {
await logFailure(endpoint, payload, error);
}
}Easy to understand, debug, no infrastructure overhead.
What Works
- Synchronous delivery from main app
- Simple database logging
- Manual retry on customer reports
- Basic error logging
Warning Signs
Watch for:
- API response times increasing during webhook peaks
- Customer complaints about delays/missing webhooks
- Timeouts on slow customer endpoints
Phase 2: 100-1K Webhooks/Hour
Real customers depend on webhooks. Reliability becomes non-negotiable.
What Breaks: Synchronous Delivery
One slow customer endpoint blocks processing for everyone. Your API slows, background jobs back up, users notice.
The Fix: Introduce a Queue
Move delivery asynchronous. Push to queue, return immediately. Separate worker handles delivery:
// Event occurs - push to queue instantly
async function onOrderCompleted(order) {
await webhookQueue.push({
type: 'order.completed',
payload: serializeOrder(order),
endpoints: await getSubscribedEndpoints(order.customerId)
});
}
// Worker processes queue independently
async function processWebhookJob(job) {
for (const endpoint of job.endpoints) {
await attemptDelivery(endpoint, job.payload);
}
}Decoupling is transformative. Main app stays fast. Customer endpoint problems become isolated incidents.
Retry Logic
With a queue, implement proper retries. Exponential backoff prevents hammering failed endpoints:
const RETRY_DELAYS = [60, 300, 1800, 7200, 86400]; // 1m, 5m, 30m, 2h, 24h
async function attemptDelivery(endpoint, payload, attempt = 0) {
try {
const response = await deliverWebhook(endpoint, payload);
if (response.ok) {
await markDelivered(endpoint, payload);
} else if (attempt < RETRY_DELAYS.length) {
await scheduleRetry(endpoint, payload, attempt + 1);
} else {
await markFailed(endpoint, payload);
}
} catch (error) {
if (attempt < RETRY_DELAYS.length) {
await scheduleRetry(endpoint, payload, attempt + 1);
} else {
await markFailed(endpoint, payload);
}
}
}Metrics to Track
- Delivery rate (target: 99%+)
- Latency p95 (target: <5 sec)
- Failure rate (target: <0.1%)
- Queue depth (should stay low)
Climbing queue depth or dropping delivery rate signals problems early.
Idempotency: Handle Duplicates Gracefully
At-least-once delivery means duplicates happen. Your handlers must be idempotent—processing the same event twice produces the same result:
async function processWebhookIdempotently(event) {
const eventKey = `${event.type}:${event.id}`;
// Check if already processed
const existing = await db.webhookEvents.findUnique({ where: { eventKey } });
if (existing?.status === 'processed') {
return { skipped: true, reason: 'duplicate' };
}
// Process with upsert to handle race conditions
await db.webhookEvents.upsert({
where: { eventKey },
create: { eventKey, status: 'processing', receivedAt: new Date() },
update: { lastAttempt: new Date() }
});
await handleEvent(event);
await db.webhookEvents.update({ where: { eventKey }, data: { status: 'processed' } });
}Three common patterns:
- Event ID tracking: Store processed IDs, skip duplicates
- Timestamp comparison: Only process if event timestamp is newer than last processed
- Idempotent operations: Design handlers so duplicates are harmless (e.g., upserts instead of inserts)
Phase 3: 1K-10K Webhooks/Hour
Scaling reveals infrastructure limits. Theoretical problems become urgent.
Challenge 1: Database Load
Every attempt generates writes. At 10K/hour with 3 retries: 30K+ ops/hour.
Solutions:
- Batch writes instead of individual inserts
- Use time-series DB for logs (optimized for append-heavy)
- Rotate and archive logs (no need for instant 6-month access)
- Separate webhook logging from main DB
Challenge 2: Retry Storms
Customer endpoint down 1 hour. All queued retries fire simultaneously when it recovers. Thousands of requests in seconds. Overwhelms queue, delays new webhooks, crashes recovering endpoint.
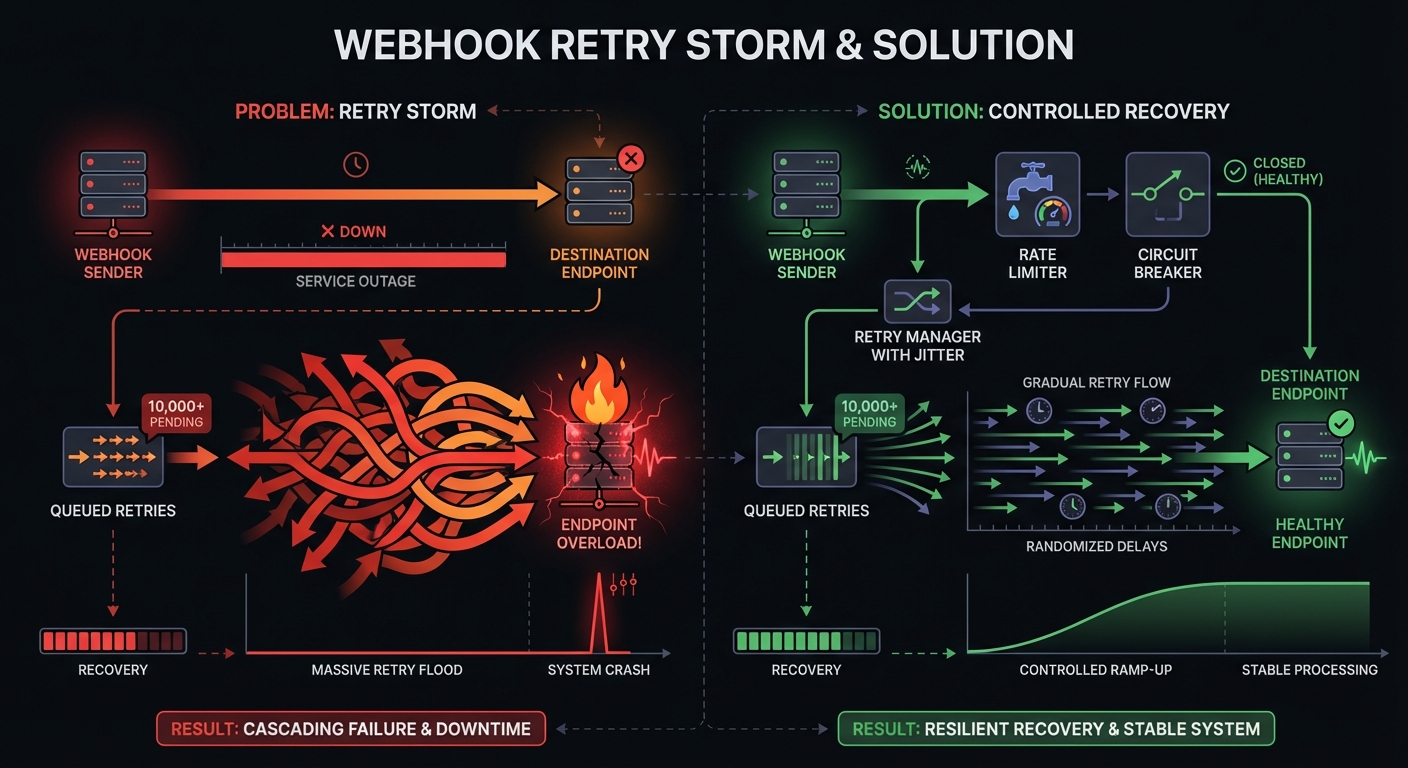
Solutions:
- Add jitter to retry timing (randomize within a window)
- Per-endpoint rate limiting
- Circuit breakers for consistently failing endpoints
- Gradually ramp up delivery on recovery
// Circuit breaker pattern with jitter
function getRetryDelayWithJitter(baseDelay) {
const jitter = Math.random() * 0.3 * baseDelay; // 0-30% jitter
return baseDelay + jitter;
}
async function checkEndpointHealth(endpoint) {
const recentFailures = await getRecentFailures(endpoint, '5m');
if (recentFailures > 10) {
await pauseEndpoint(endpoint, '15m');
await notifyCustomer(endpoint, 'Endpoint paused due to failures');
return false;
}
return true;
}Challenge 3: Queue Management
Simple Redis queues struggle at 10K. Need visibility, prioritization, graceful backlog handling.
Considerations:
- Dead letter queues for permanent failures
- Priority lanes for time-sensitive events (payment webhooks > analytics)
- Monitor consumer lag, scale workers based on queue depth
- Consider managed queues (SQS, Cloud Tasks) for auto-scaling
Challenge 4: Hot Endpoints
One customer receives 80% of your webhooks. Their endpoint slows, your entire queue backs up.
Solutions:
- Per-endpoint queues or partitioning
- Concurrency limits per customer
- Separate worker pools for high-volume customers
- Backpressure detection: pause delivery when endpoint response times spike
Monitoring & Alerting
Proactive alerting essential at this volume. Define SLOs (Service Level Objectives) tied to business impact:
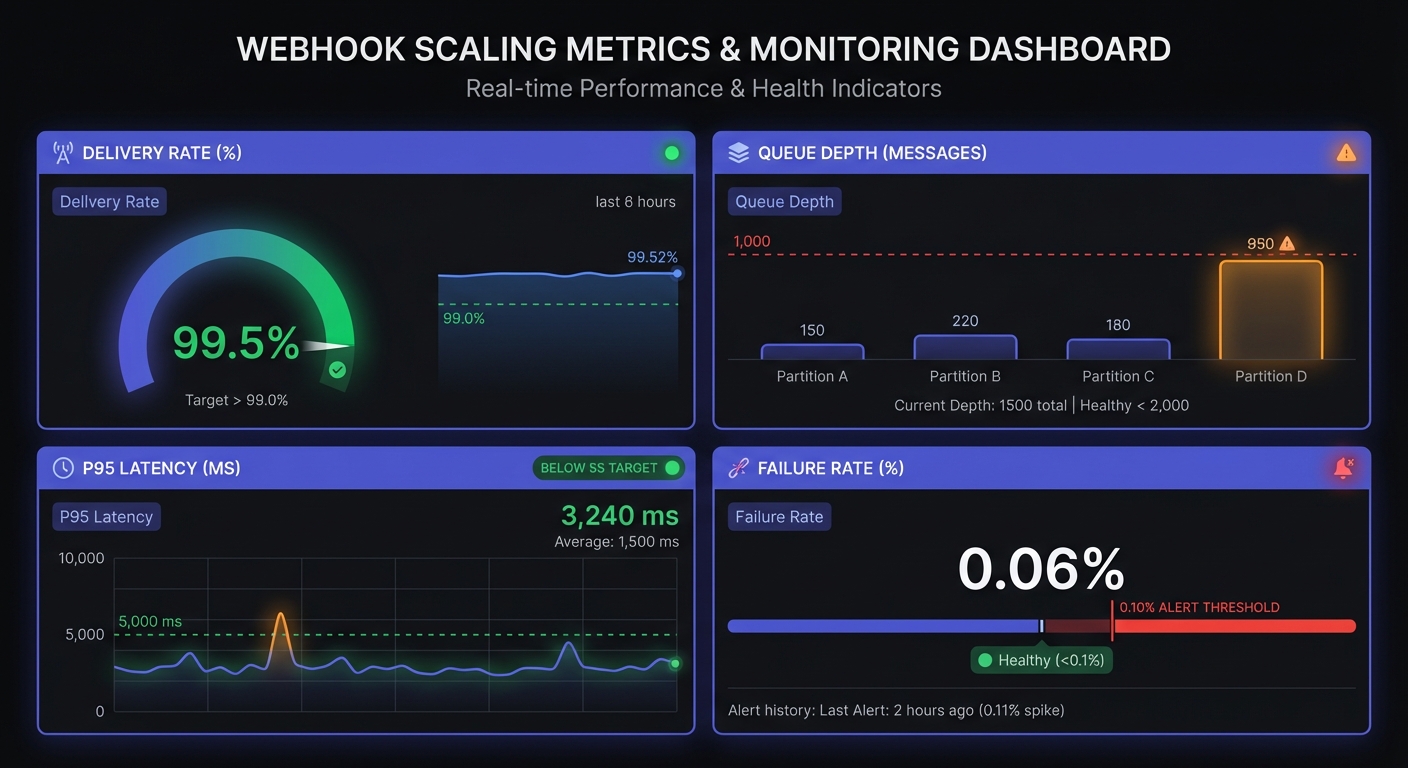
Key SLOs for webhook delivery:
| Metric | Target | Alert Threshold |
|---|---|---|
| Delivery rate | 99.5% | <98% |
| P95 latency | <5 sec | >30 sec |
| Queue depth | Near zero | Sustained >1000 |
| Failure rate | <0.1% | >1% |
Track these with proper observability:
- Queue depth + max age: Detect backpressure before it cascades
- Estimated drain time: Predict when backlogs clear
- Per-endpoint failure rates: Isolate problem customers quickly
Set up on-call rotations. Webhook failures at 3 AM affect customers' businesses.
Beyond 10K: Event Destinations
At extreme scale (100K+/hour), HTTP webhooks hit fundamental limits. Modern platforms like Stripe and Shopify now support event destinations—direct delivery to message buses:
- Amazon EventBridge
- Google Cloud Pub/Sub
- Amazon Kinesis
This bypasses HTTP entirely. No timeouts, no retries, no authentication handshakes. Events flow directly into your event infrastructure. If you're building for massive scale, design your architecture to support both traditional webhooks and event destinations.
When DIY Stops Making Sense
Teams discover:
Maintenance grows faster than expected. Edge cases (slow endpoints, DNS failures, SSL problems) accumulate complexity.
Customer expectations increase. Enterprise customers expect 99.99% delivery, detailed logs, same-day resolution.
Opportunity cost rises. Engineers debugging retry logic could ship differentiating features.
Math changes at 10K/hr: Managed service costs a few hundred $/month. Less than hours of engineering time—and you spend far more on maintenance. See our build vs buy analysis for detailed cost comparisons.
Signs to Consider Managed Services
- Spending >few hours/week on webhook infrastructure
- Customers report undiagnosable delivery issues
- Scaling queue workers is routine
- Building features services already provide
- Engineer departure creates knowledge gap
Conclusion
Scaling from 0 to 10K/hour is predictable. Synchronous works at launch, breaks when reliability matters. Simple queues scale poorly. DIY systems become distractions from core product.
Every startup reaches the point where webhook infrastructure stops being an advantage and becomes a tax on engineering time. Recognizing that transition is the difference between smooth and painful scaling.
Queue your delivery, implement retries, monitor, and know when to rent expertise rather than build it. Your customers depend on reliable webhooks. How you deliver that reliability matters less than delivering it.
For your MVP webhook architecture, start simple. Add complexity only when metrics demand it. And when infrastructure maintenance exceeds feature development time, consider managed solutions like Hook Mesh that handle scaling automatically.
Related Posts
MVP Webhook Architecture: Start Simple, Scale Later
A practical guide for startups building their first webhook system. Learn what you need on day one versus later, avoid common over-engineering mistakes, and understand when to build versus buy.
Webhook Circuit Breakers: Protect Your Infrastructure
Learn how to implement the circuit breaker pattern for webhook delivery to prevent cascading failures, handle failing endpoints gracefully, and protect your infrastructure from retry storms.
Webhook Rate Limiting: Strategies for Senders and Receivers
A comprehensive technical guide to webhook rate limiting covering both sender and receiver perspectives, including implementation strategies, code examples, and best practices for handling high-volume event delivery.
Build vs Buy: Webhook Infrastructure Decision Guide
A practical guide for engineering teams deciding whether to build webhook delivery infrastructure from scratch or use a managed service. Covers engineering costs, timelines, and when each approach makes sense.
Webhook Observability: Logging, Metrics, and Tracing
A comprehensive technical guide to implementing observability for webhook systems. Learn about structured logging, key metrics to track, distributed tracing with OpenTelemetry, and alerting best practices.