How to Scope Your Webhook MVP (Without Over-Engineering)
A practical guide for product managers and engineers on scoping a webhook MVP. Learn what features to include, what to defer, how to prioritize events, and avoid common scope creep traps that derail webhook projects.
How to Scope Your Webhook MVP (Without Over-Engineering)
You've decided your product needs webhooks. The temptation is to over-engineer: message queues, exponential backoff, event sourcing. Before you know it, a "simple feature" becomes a three-month infrastructure project.
Webhook infrastructure sounds simple—send an HTTP POST when something happens. But as any team that's shipped webhooks to production knows, the difference between a basic implementation and reliable delivery at scale involves retry logic, monitoring, security, and operational overhead that most teams underestimate.

This guide covers what belongs in MVP, what to defer, how to prioritize events, and avoid the scope creep traps that derail webhook projects.
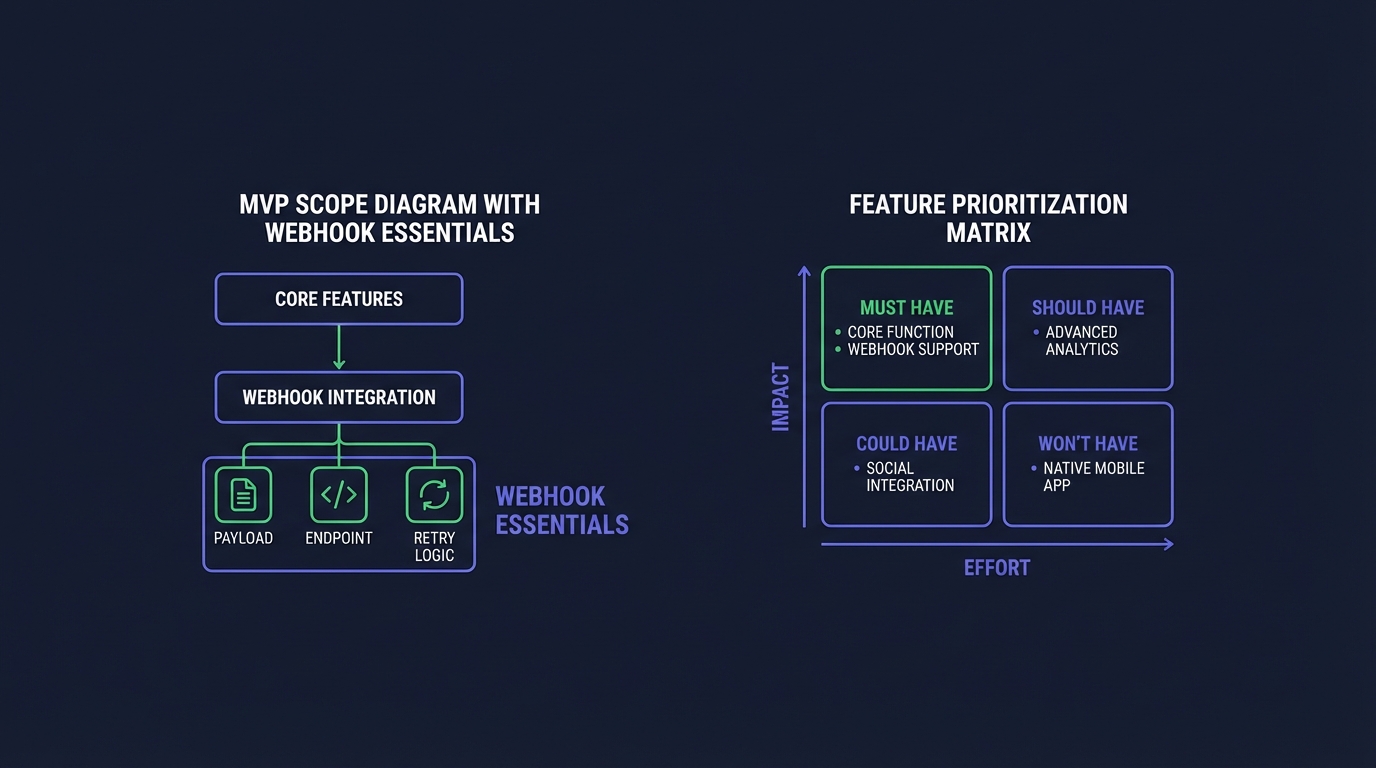
Essential MVP Features
Your webhook MVP needs five non-negotiable capabilities. Skip any of these and you'll ship something customers can't trust.
Reliable Delivery With Retries
Endpoints fail. Automatic retry logic with exponential backoff is non-negotiable. A reasonable MVP schedule: 5 min, 30 min, 2 hrs, 8 hrs, 24 hrs—giving endpoints 35+ hours to recover.
Add jitter to prevent thundering herd problems when multiple webhooks retry simultaneously. Without jitter, retries can overwhelm recovering endpoints.
Payload Signatures
Sign every webhook with HMAC-SHA256 signatures so recipients verify authenticity. Non-negotiable for production.
Include a timestamp in your signature to prevent replay attacks. Most providers (Stripe, GitHub, Shopify) follow this pattern.
Delivery Logs
Log every attempt with timestamp, response code, and body. 7 days retention is enough for MVP.
Searchable logs serve dual purposes: customer debugging and your own support triage. When a customer reports "missing webhooks," logs are your first defense.
Event Type Filtering
Let customers subscribe to specific events. Nobody wants all user.updated webhooks when they only need payment.succeeded.
This reduces noise for customers and load on your infrastructure. Start with 5-10 event types maximum.
HTTPS Enforcement
Never deliver over plain HTTP. This protects customer data and is expected by any production system.
Async Processing Pattern
Separate webhook ingestion from processing. Your endpoint's job: receive, validate signature, queue, return 200. Processing happens in background workers.
// Endpoint: receive and acknowledge
app.post('/webhook', async (req, res) => {
if (!verifySignature(req)) {
return res.status(401).send('Invalid signature');
}
await queue.add('webhook', req.body);
res.status(200).send('OK'); // Acknowledge immediately
});
// Worker: process asynchronously
queue.process('webhook', async (job) => {
await processWebhook(job.data);
});This pattern prevents timeout issues and allows graceful handling of downstream failures.
Defer These Features
- Payload transformations - Complex; customers can transform on their end for now
- Advanced filtering - (e.g., "order total > $100") adds significant complexity
- Bulk replay - Single replay is essential; thousands at once is advanced
- Multiple secret versions - Important for enterprise, overkill for MVP
- Custom retry schedules - Add complexity; sensible defaults work
- Message broker integrations - Valuable for high-volume but adds infrastructure complexity
- Webhook testing UI - Use webhook.site or ngrok; build custom tools later
MVP enables core functionality. Deferred features add flexibility. Ship core first, learn from customers, build later.
Prioritizing Events
Use a prioritization matrix. Evaluate each event across three dimensions:
| Factor | Low (1) | Medium (2) | High (3) |
|---|---|---|---|
| Customer Demand | No requests | Occasional mentions | Frequently requested |
| Technical Complexity | Requires new infrastructure | Moderate changes | Already have the data |
| Business Value | Nice to have | Enables integrations | Blocks deals |
Example for a billing SaaS:
| Event | Demand | Complexity | Value | Total |
|---|---|---|---|---|
payment.succeeded | 3 | 3 | 3 | 9 |
subscription.cancelled | 3 | 3 | 3 | 9 |
invoice.created | 2 | 3 | 2 | 7 |
payment.failed | 2 | 3 | 2 | 7 |
High-scoring events are MVP candidates; lower-scoring ones can wait.
The MoSCoW Method
An alternative framework for categorizing webhook features:
| Category | Definition | MVP Examples |
|---|---|---|
| Must Have | Critical for launch | Retries, signatures, HTTPS |
| Should Have | Important but not critical | Event filtering, logs UI |
| Could Have | Nice additions | Custom headers, payload preview |
| Won't Have | Explicitly deferred | Transformations, bulk replay |
Document your categorization in writing. When stakeholders suggest new features mid-development, reference this document.
Start With 5-10 Events
Resist exposing 50 types immediately:
- Faster time to market
- Room to iterate based on real usage
- Simpler for customers to understand
- Easier documentation to maintain
Adding events is easy; removing them later is hard. Each event becomes a contract with your customers.
Build vs Buy
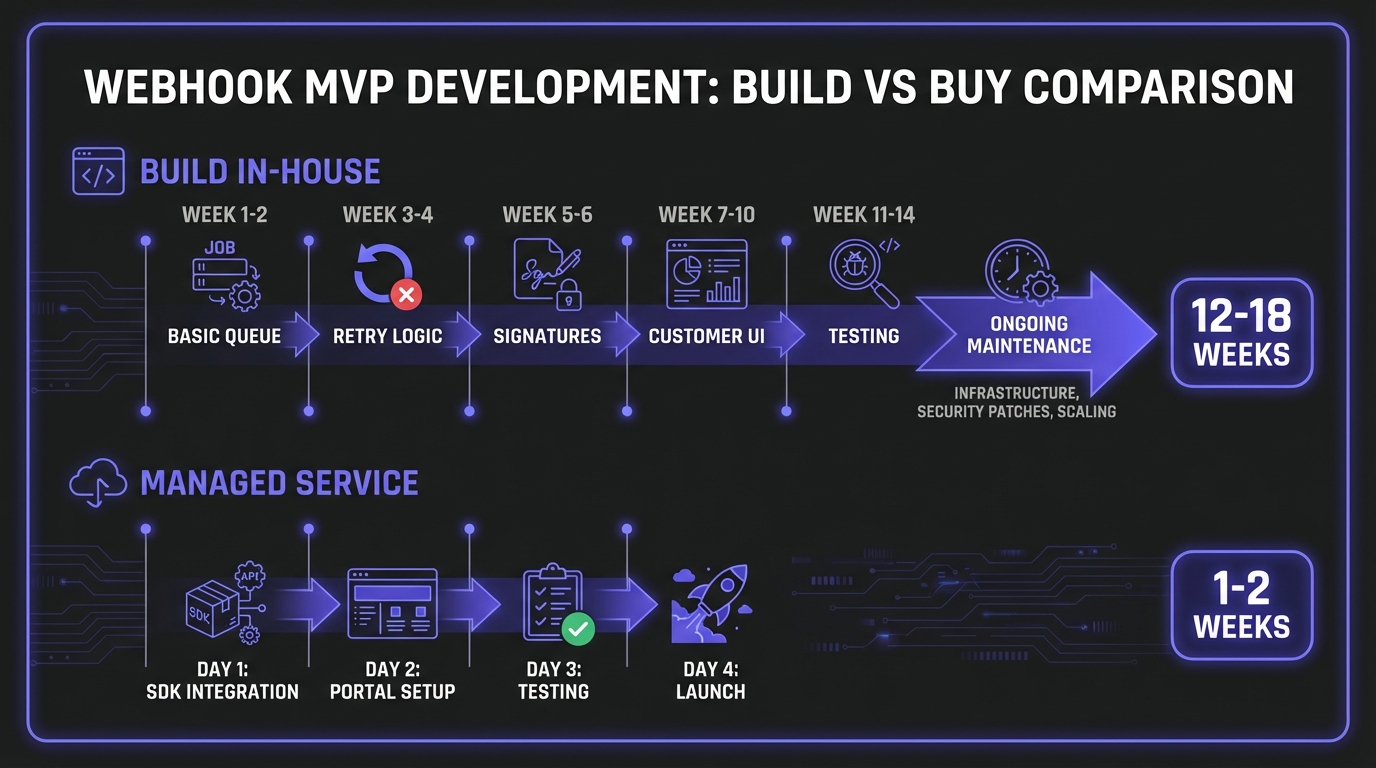
The build decision often underestimates hidden costs. Teams estimate 6-8 weeks; reality delivers 12-18 weeks. The gap comes from edge cases, customer debugging, and the inevitable "one more feature" requests.
Build Estimates
| Component | Estimated | Reality |
|---|---|---|
| Basic delivery (queue + HTTP) | 1-2 wks | 2-4 wks |
| Retry logic | 1 wk | 2-3 wks |
| Signatures | 2-3 days | 1 wk |
| Logging | 1 wk | 2-3 wks |
| Customer UI | 2-3 wks | 4-6 wks |
| Docs | 1 wk | 2 wks |
| Initial total | 6-8 wks | 12-18 wks |
Plus ongoing: customer debugging, edge cases, scaling, UI maintenance, security patches.
Teams spend 20-30% of one engineer's time maintaining webhook infrastructure. That's 1-2 days per week not spent on your core product.
Hidden Costs of Building
Beyond development time, consider:
- Opportunity cost: Engineers maintaining plumbing instead of shipping features
- Incident response: Missed webhooks cause customer churn
- Scaling surprises: Traffic spikes break unprepared systems
- Security maintenance: Vulnerabilities require immediate patches
When Building Makes Sense
Building your own solution is justified when:
- Webhooks ARE your product (you're building a webhook service)
- Extreme customization requirements exist
- Regulatory requirements mandate full control
- You have dedicated infrastructure team bandwidth
For most startups, these conditions don't apply.
Managed Service
| Component | Time |
|---|---|
| SDK integration | 1-2 days |
| Customer portal | 1-2 days |
| Documentation | 2-3 days |
| Testing & QA | 2-3 days |
| Total | 1-2 weeks |
Live in days, not months. The service handles retries, logging, UI, and scaling automatically. For most startups, engineering time is your scarcest resource.
Hook Mesh provides all MVP essentials out of the box: retries with exponential backoff, HMAC signatures, delivery logs, event filtering, and a customer portal. See our build vs buy analysis for detailed comparison.
Scope Creep Traps
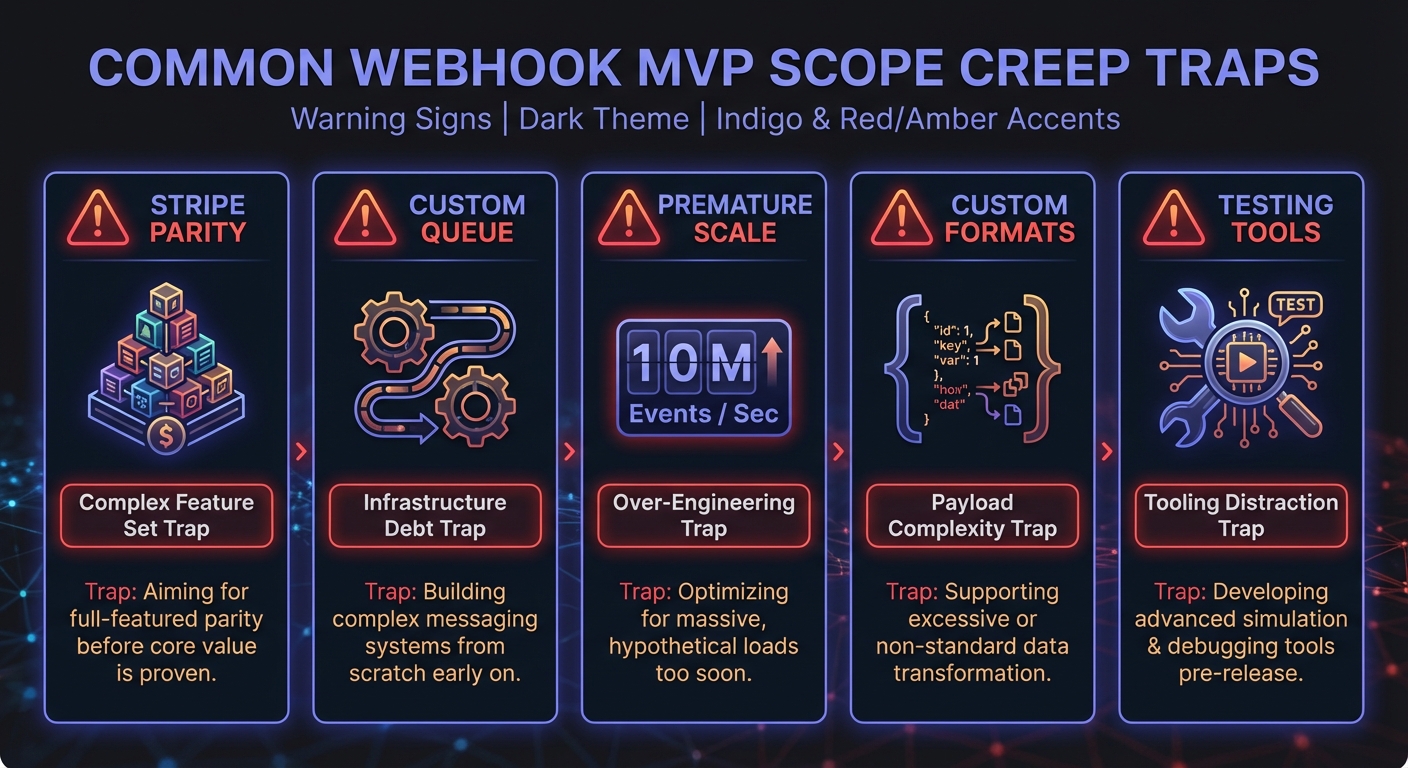
Trying to support every desired feature leads to generic solutions that solve every known problem—except shipping on time. Each architectural characteristic requires design effort and structural support, and each impacts others.
Trap 1: Stripe Feature Parity
Stripe invested millions over a decade. You don't need parity for MVP.
Solution: Define MVP features in writing. When a new feature is suggested, ask: "Required for first 10 customers?" If not, defer it.
Trap 2: Build Your Own Queue
Use existing infrastructure (Redis, SQS, RabbitMQ) or a managed service.
Solution: Treat infrastructure as solved. Your advantage isn't in queue design.
A hybrid approach works: use cloud services (AWS SQS, Redis) for queuing while building custom logic on top. Don't reinvent message delivery.
Trap 3: Premature Scale
"What if we need 10M webhooks/day?" You're not there yet. Premature optimization slows you down.
Solution: Build for 10x current scale, not 1000x. When you hit 10x, you'll have revenue and data to inform the next scaling decision.
Trap 4: Custom Payload Formats
Customers might want custom formats. They can transform on their end for MVP.
Solution: Ship a standard JSON format. Add flexibility when customers explicitly request it with real use cases.
Trap 5: Custom Testing Tool
Testing tools add scope. Use webhook.site for MVP testing.
Solution: Provide sample payloads in docs. Build your own tooling later if demand justifies it.
Trap 6: Perfect Idempotency
Building bullet-proof idempotency takes time. For MVP, document that you deliver at-least-once and recommend customers handle duplicates.
Solution: Include unique event IDs in payloads. Customers can deduplicate on their end initially.
Endpoint Status and Health
Track endpoint health to protect your infrastructure and notify customers of problems.
Basic Status Tracking
const endpointHealth = {
endpoint_id: 'ep_123',
consecutive_failures: 0,
last_success: '2026-01-21T10:00:00Z',
status: 'active' // active, degraded, disabled
};
// After each delivery attempt
if (response.ok) {
endpointHealth.consecutive_failures = 0;
endpointHealth.last_success = new Date().toISOString();
endpointHealth.status = 'active';
} else {
endpointHealth.consecutive_failures++;
if (endpointHealth.consecutive_failures >= 10) {
endpointHealth.status = 'disabled';
notifyCustomer(endpointHealth.endpoint_id);
}
}Customer Notifications
When endpoints fail repeatedly:
- Mark endpoint as degraded after 5 consecutive failures
- Disable endpoint after 10 failures
- Email customer with failure details and re-enable instructions
This prevents wasting resources on dead endpoints while keeping customers informed.
Your Webhook MVP Checklist
Use this checklist to ensure your webhook MVP is properly scoped:
Core Delivery
- Automatic retries with exponential backoff (at least 5 attempts over 24+ hours)
- Jitter on retry delays to prevent thundering herd
- HMAC-SHA256 payload signatures with timestamp
- HTTPS-only delivery
- Configurable timeout (15-30 seconds is reasonable)
- Async processing (queue webhooks, process in workers)
Customer Experience
- Event type filtering (subscribe to specific events)
- Delivery logs visible to customers (at least 7 days)
- Manual replay for failed deliveries
- Clear endpoint status indicators
- Email notifications for disabled endpoints
Developer Experience
- REST API for programmatic management
- Well-documented event catalog
- Sample payloads for each event type
- Verification code samples (Node.js, Python at minimum)
- Unique event IDs for customer-side deduplication
Deferred for Later
- Payload transformations
- Advanced filtering rules
- Bulk replay
- Secret rotation with grace periods
- Custom retry schedules
- Message broker integrations
- Custom testing UI
Launch Path
Reliable delivery, retry logic, customer UI, logging, and maintenance equal significant investment. Define your MVP in writing, stick to it, and ship.
Launch timeline with a managed service:
- Day 1: SDK integration, define events
- Day 2: Embed portal, write docs
- Day 3: End-to-end testing
- Day 4: Ship
Launch timeline building in-house (realistic):
- Weeks 1-4: Core delivery infrastructure
- Weeks 5-8: Customer UI and logs
- Weeks 9-12: Testing, edge cases, security review
- Weeks 13+: Customer feedback and iteration
Your team should build features that differentiate your product, not reinvent webhook infrastructure.
For startups focused on shipping fast, Hook Mesh provides the complete MVP feature set with pricing designed for startups—free tier included.
Related Posts
MVP Webhook Architecture: Start Simple, Scale Later
A practical guide for startups building their first webhook system. Learn what you need on day one versus later, avoid common over-engineering mistakes, and understand when to build versus buy.
Webhooks for Startups: A Practical Guide
A comprehensive guide for startup founders and engineers on implementing webhooks - when to add them, what to build first, and how to scale without over-engineering.
When Should Your Startup Add Webhooks?
A practical decision guide for startup founders and product managers on the right time to invest in webhook infrastructure, what signs to watch for, and how to avoid common timing mistakes.
5 Webhook Mistakes Early-Stage Startups Make
Learn the most common webhook mistakes that plague early-stage startups—from missing retry logic to over-engineering—and how to avoid them before they cost you customers.
How to Add Webhooks to Your SaaS Product in 2026
A complete guide for SaaS founders and engineers on implementing webhooks—from event design and payload structure to build vs buy decisions and customer experience best practices.