MVP Webhook Architecture: Start Simple, Scale Later
A practical guide for startups building their first webhook system. Learn what you need on day one versus later, avoid common over-engineering mistakes, and understand when to build versus buy.
MVP Webhook Architecture: Start Simple, Scale Later
Customers want webhooks. Your instinct: research distributed systems, design for millions of events per second.
Stop. Most startups over-engineer on day one, spending months on infrastructure they won't need for years. Competitors ship in days.
This guide shows what you need at each growth stage—and what to deliberately defer.
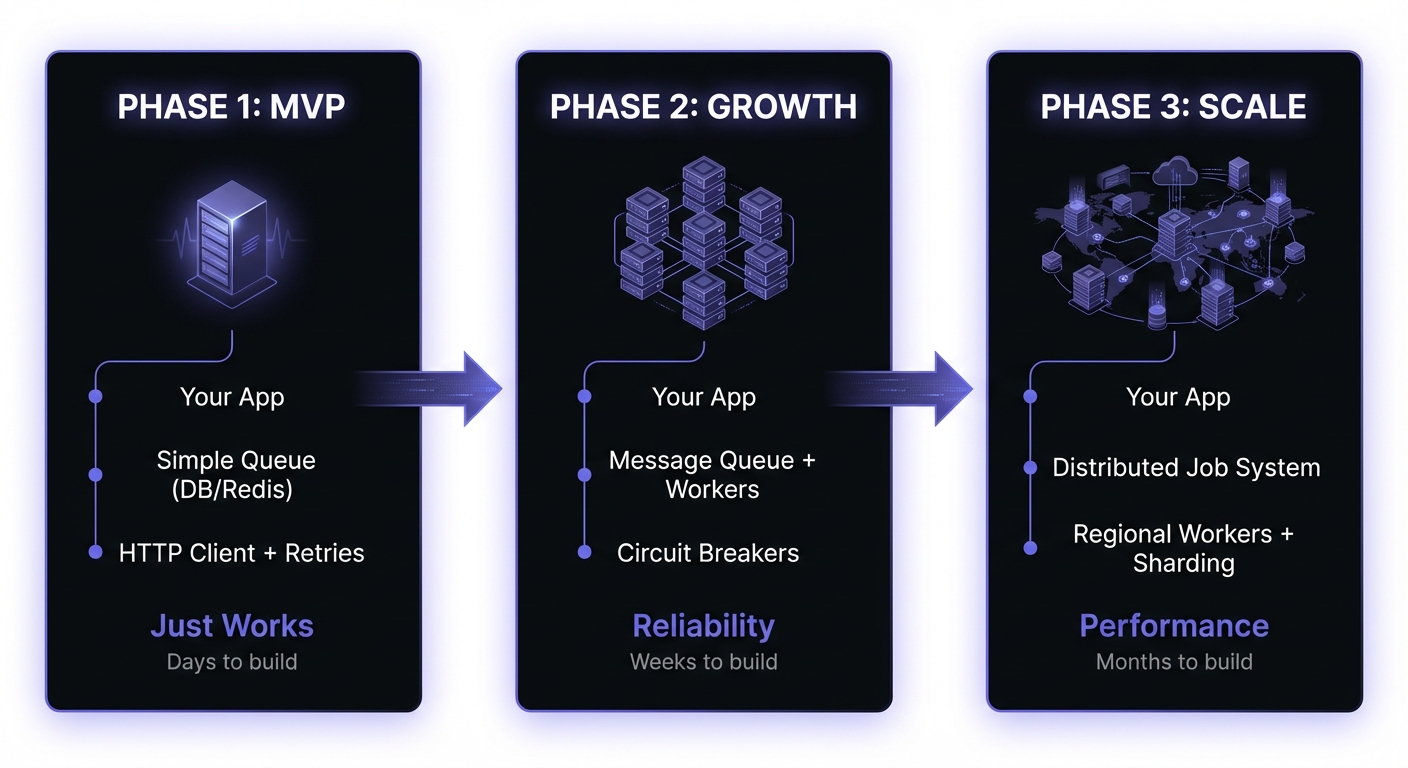
The Three Phases of Webhook Architecture
Webhook infrastructure evolves with your business. What works for 1,000 events per day is different from what you need at 1 million. Understanding these phases helps you invest appropriately at each stage.
PHASE 1: MVP PHASE 2: GROWTH PHASE 3: SCALE
(Just Works) (Reliability) (Performance)
+--------------+ +--------------+ +-----------------+
| Your App | | Your App | | Your App |
+------+-------+ +------+-------+ +--------+--------+
| | |
v v v
+--------------+ +--------------+ +-----------------+
| Simple Queue | | Message Queue| | Distributed |
| (DB or Redis)| | + Workers | | Job System |
+------+-------+ +------+-------+ +--------+--------+
| | |
v v v
+--------------+ +--------------+ +-----------------+
| HTTP Client | | Worker Pool | | Regional Workers|
| with Retries | | + Circuit | | + Rate Limiting |
+--------------+ | Breakers | | + Sharding |
+--------------+ +-----------------+
Phase 1: MVP (Just Works)
Validate that customers want webhooks and which events matter. Architecture should be buildable in a day or two.
Database Schema
Start with a simple events table. This schema handles queuing, delivery tracking, and retry logic:
CREATE TABLE webhook_events (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
endpoint_url VARCHAR(2048) NOT NULL,
endpoint_secret VARCHAR(255) NOT NULL,
event_type VARCHAR(100) NOT NULL,
payload JSONB NOT NULL,
status VARCHAR(20) DEFAULT 'pending', -- pending, delivered, failed
attempts INT DEFAULT 0,
max_attempts INT DEFAULT 3,
next_attempt_at TIMESTAMP DEFAULT NOW(),
last_error TEXT,
created_at TIMESTAMP DEFAULT NOW(),
delivered_at TIMESTAMP
);
CREATE INDEX idx_pending_events ON webhook_events (next_attempt_at)
WHERE status = 'pending';The next_attempt_at index makes polling efficient. Query pending events with WHERE status = 'pending' AND next_attempt_at <= NOW().
HTTP Delivery With Retries
Send an HTTP POST to the endpoint. Retry on failure with delays:
async function sendWebhook(endpoint, payload, attempt = 1) {
const maxRetries = 3;
const baseDelay = 5000; // 5 seconds
try {
const response = await fetch(endpoint.url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Webhook-Signature': signPayload(payload, endpoint.secret),
'X-Webhook-Timestamp': Date.now().toString()
},
body: JSON.stringify(payload),
signal: AbortSignal.timeout(10000) // 10 second timeout
});
if (!response.ok && attempt < maxRetries) {
const delay = baseDelay * Math.pow(2, attempt - 1);
await sleep(delay);
return sendWebhook(endpoint, payload, attempt + 1);
}
return { success: response.ok, status: response.status };
} catch (error) {
if (attempt < maxRetries) {
const delay = baseDelay * Math.pow(2, attempt - 1);
await sleep(delay);
return sendWebhook(endpoint, payload, attempt + 1);
}
return { success: false, error: error.message };
}
}Signatures
Sign every webhook with HMAC-SHA256 so customers verify authenticity:
function signPayload(payload, secret) {
const timestamp = Date.now();
const signedContent = `${timestamp}.${JSON.stringify(payload)}`;
return crypto
.createHmac('sha256', secret)
.update(signedContent)
.digest('hex');
}Logging
Log every attempt with endpoint, status code, and timestamp:
async function logDelivery(eventId, endpointId, result) {
await db.webhookLogs.create({
event_id: eventId,
endpoint_id: endpointId,
status: result.success ? 'delivered' : 'failed',
http_status: result.status,
error: result.error,
attempted_at: new Date()
});
}Testing Locally
Use tunneling tools to test webhook delivery against your local development environment:
- ngrok:
ngrok http 3000exposes localhost with a public URL - webhook.site: Captures payloads for inspection without writing code
- Stripe CLI:
stripe listen --forward-to localhost:3000/webhooksfor Stripe-style testing
Test these scenarios before shipping:
- Timeout handling (endpoint takes > 10 seconds)
- Non-2xx responses (4xx vs 5xx behavior)
- Signature verification failure
- Malformed payload handling
Defer
At MVP stage, avoid:
- FIFO ordering (handle at consumer with timestamps)
- Complex retry schedules (3 retries is fine)
- Multi-region (if your main app isn't, webhooks don't need it)
- Payload transformations (same format for everyone)
- Idempotency infrastructure (include event ID, document duplicate handling)
Phase 2: Growth (Reliability)
Volume is growing. Slow endpoints block delivery, customers complain about missed events. Reliability becomes critical.
Add at Growth Stage
Async processing with a queue
Move delivery off your main request path. Use Redis, SQS, or database-backed queue:
+------------+ +--------+ +-------------+
| Your App |---->| Queue |---->| Worker Pool |---->| Customer |
| (Producer) | | (Redis)| | (Consumers) | | Endpoint |
+------------+ +--------+ +-------------+
Circuit breakers
When endpoints fail repeatedly, stop hammering them. Protects both you and the customer:
class CircuitBreaker {
constructor(threshold = 5, resetTimeout = 300000) {
this.failures = 0;
this.threshold = threshold;
this.resetTimeout = resetTimeout; // 5 minutes
this.state = 'closed';
this.lastFailure = null;
}
recordFailure() {
this.failures++;
this.lastFailure = Date.now();
if (this.failures >= this.threshold) {
this.state = 'open';
}
}
recordSuccess() {
this.failures = 0;
this.state = 'closed';
}
canAttempt() {
if (this.state === 'closed') return true;
if (Date.now() - this.lastFailure > this.resetTimeout) {
this.state = 'half-open';
return true;
}
return false;
}
}Extended retry window
Move from minutes to hours: immediate, 5m, 30m, 2h, 6h, 24h.
Customer-facing delivery logs
Let customers see webhook status. Dramatically reduces support burden.
Dead letter queues
Events that fail all retries need a destination. Store them separately for manual investigation:
CREATE TABLE webhook_dead_letters (
id UUID PRIMARY KEY,
original_event_id UUID REFERENCES webhook_events(id),
endpoint_url VARCHAR(2048) NOT NULL,
payload JSONB NOT NULL,
last_error TEXT,
attempts INT,
failed_at TIMESTAMP DEFAULT NOW(),
resolved_at TIMESTAMP,
resolution_notes TEXT
);Review dead letters weekly. Common patterns: expired SSL certificates, changed endpoint URLs, authentication failures.
Basic observability
Track these metrics from day one:
- Delivery success rate (target: > 95%)
- Average delivery latency (target: < 2 seconds for first attempt)
- Retry rate (high retry rate signals endpoint issues)
- Dead letter queue depth (growing queue needs investigation)
A simple dashboard query:
SELECT
DATE_TRUNC('hour', created_at) AS hour,
COUNT(*) AS total_events,
COUNT(*) FILTER (WHERE status = 'delivered') AS delivered,
COUNT(*) FILTER (WHERE status = 'failed') AS failed,
AVG(EXTRACT(EPOCH FROM (delivered_at - created_at))) AS avg_latency_seconds
FROM webhook_events
WHERE created_at > NOW() - INTERVAL '24 hours'
GROUP BY 1 ORDER BY 1;Still Defer
- Strict ordering (unless customers complain)
- Global rate limiting (per-endpoint is usually sufficient)
- Complex payload transformations
Phase 3: Scale (Performance)
Processing millions daily. Reliability is stable; performance and cost become concerns.
You may need:
- Database-as-queue patterns to avoid bottlenecks
- Per-tenant isolation (prevent noisy neighbors)
- Regional workers for latency
- Sophisticated per-endpoint rate limiting
- Sharded databases for logs
If you're at Phase 3, see scaling webhooks from 0 to 10K.
Over-Engineering Traps
Building for imaginary scale Designing for 10M events/day when you process 1K. Enterprise systems take months to build and harder to modify.
Strict ordering from day one FIFO across distributed systems is hard. Most webhooks don't need it. Consumers can sort with timestamps.
Premature multi-region Cross-region replication, split-brain scenarios, distributed debugging. If your core app isn't multi-region, webhooks shouldn't be.
Custom retry schedules per endpoint Sounds flexible; in practice, you spend more time explaining than customers benefit. Standard schedules work for almost everyone.
Customer portal too early Delivery logs and replay are important. Build an API first. Add UI when you have enough customers.
Build vs Buy
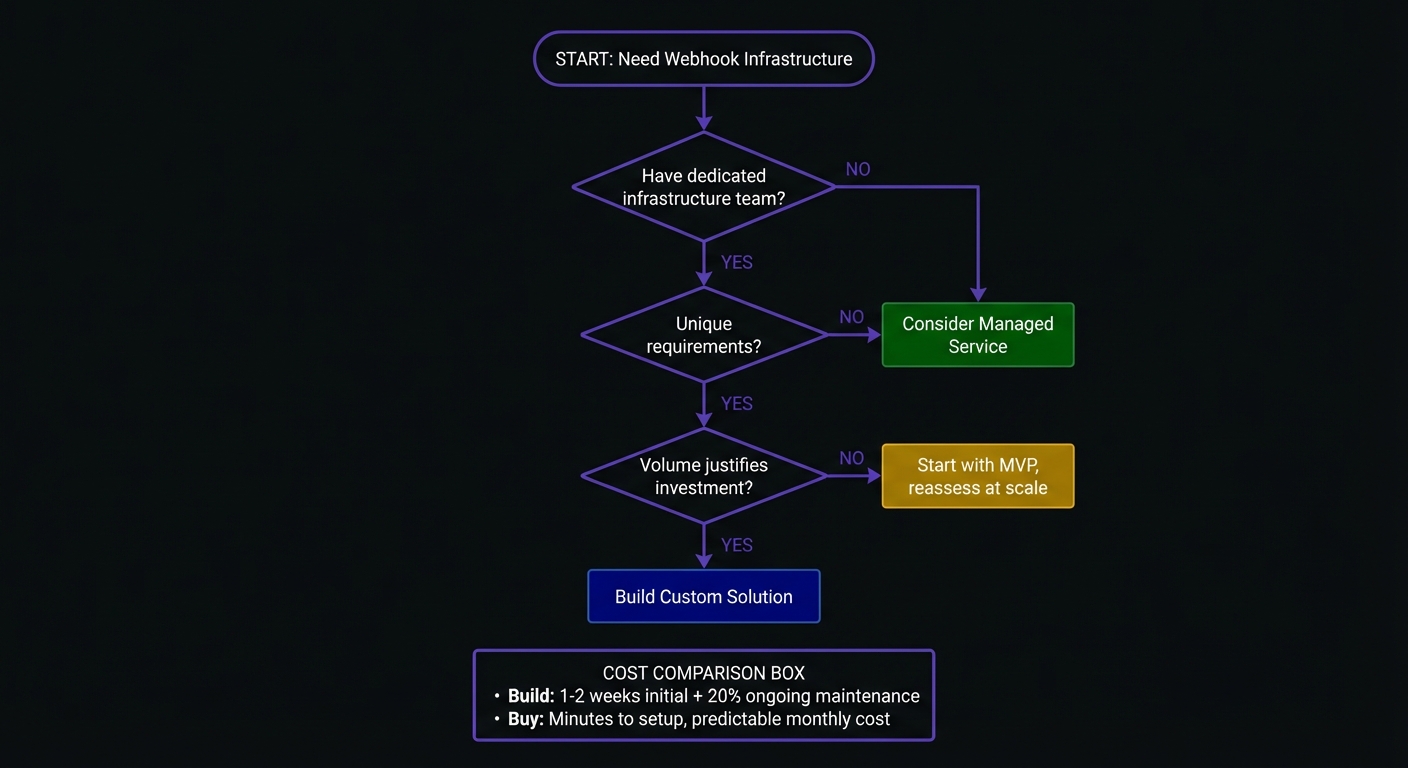
Build if:
- You want full control
- Requirements are unusual
- You have dedicated infrastructure engineers
- Volume justifies investment
Buy if:
- Team should focus on core product
- You need webhooks in days, not months
- Operational burden isn't appealing
- You need reliability features immediately
The math: Phase 1 takes 1-2 weeks. Then maintenance, Phase 2 features, customer debugging, scaling. A senior engineer at 20% cost exceeds managed services.
For a detailed analysis, see build vs buy webhook infrastructure and the true cost of building webhooks in-house.
A Practical Starting Point
If you're determined to build, here's a minimal architecture that's good enough for MVP and won't paint you into a corner:
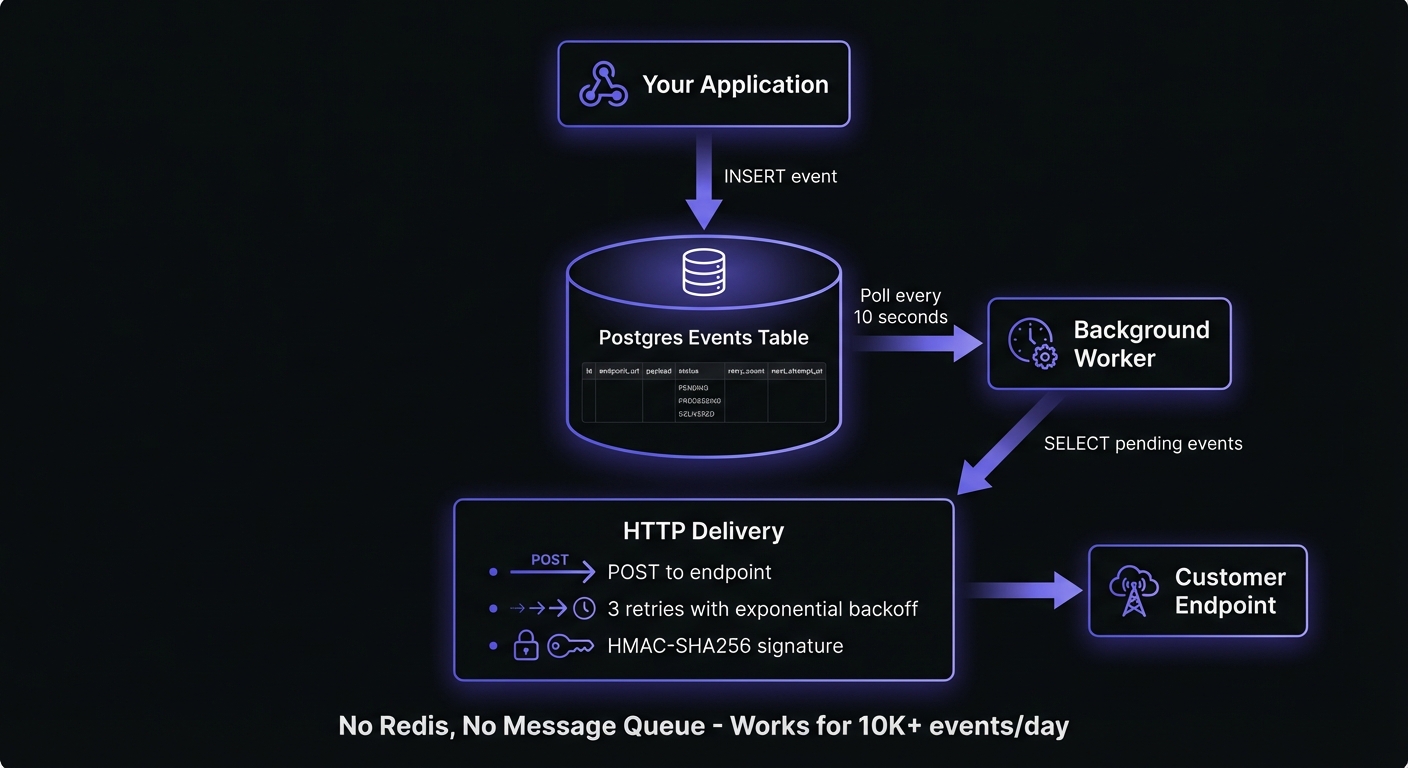
+------------------+
| Your App |
+--------+---------+
|
v
+------------------+ +------------------+
| Events Table |---->| Background Job |
| (Postgres) | | (Cron every 10s) |
+------------------+ +--------+---------+
|
v
+------------------+
| Delivery Worker |
| - HTTP client |
| - 3 retries |
| - Signatures |
+------------------+
Postgres table + cron job + delivery function. No Redis, no distributed systems. Works for thousands of events/day.
Cost at Each Phase
Understanding infrastructure costs helps timing decisions:
| Phase | Monthly Cost | Events/Day | Team Time |
|---|---|---|---|
| MVP | $0-50 (existing DB) | 1K-10K | 2-4 hours/month |
| Growth | $100-500 (Redis + workers) | 10K-100K | 1-2 days/month |
| Scale | $1K-5K+ (distributed infra) | 100K-1M+ | Dedicated engineer |
Compare against managed services: most charge $0.001-0.01 per webhook. At 100K events/day, that's $100-1000/month—often cheaper than engineering time for Growth/Scale phases.
When you outgrow it, invest in real infrastructure or use a managed service.
Delivery Guarantees
Understand what you're promising customers:
At-least-once delivery (recommended for MVP): Events may be delivered multiple times. Simpler to implement, requires customers to handle idempotency. This is what Stripe, GitHub, and most providers offer.
At-most-once delivery: Events delivered zero or one time. Simpler for customers but unacceptable for critical events like payments.
Exactly-once delivery: Extremely difficult to achieve in distributed systems. Requires coordination between your system and the customer's—not practical for webhooks.
Document your guarantee clearly. Most customers expect at-least-once and will build idempotent handlers.
Conclusion
The best webhook architecture is the simplest one that works. Day one: retries, signatures, logging. Everything else waits.
Don't build what Stripe has. They've spent years on this. You have a product to ship.
Start simple. Scale later.
For detailed guidance on scoping your webhook MVP or understanding webhook retry strategies, explore our related guides.
Related Posts
How to Scope Your Webhook MVP (Without Over-Engineering)
A practical guide for product managers and engineers on scoping a webhook MVP. Learn what features to include, what to defer, how to prioritize events, and avoid common scope creep traps that derail webhook projects.
Webhooks for Startups: A Practical Guide
A comprehensive guide for startup founders and engineers on implementing webhooks - when to add them, what to build first, and how to scale without over-engineering.
From 0 to 10K Webhooks: Scaling Your First Implementation
A practical guide for startups on how to scale webhooks from your first implementation to handling 10,000+ events per hour. Learn what breaks at each growth phase and how to fix it before your customers notice.
Webhook Retry Strategies: Linear vs Exponential Backoff
A technical deep-dive into webhook retry strategies, comparing linear and exponential backoff approaches, with code examples and best practices for building reliable webhook delivery systems.
Build vs Buy: Webhook Infrastructure Decision Guide
A practical guide for engineering teams deciding whether to build webhook delivery infrastructure from scratch or use a managed service. Covers engineering costs, timelines, and when each approach makes sense.