Webhook Retry Strategies: Linear vs Exponential Backoff
A technical deep-dive into webhook retry strategies, comparing linear and exponential backoff approaches, with code examples and best practices for building reliable webhook delivery systems.

Webhook Retry Strategies: Linear vs Exponential Backoff
When a webhook fails, what happens next determines whether it recovers silently or breaks the integration. This deep-dive explores the mathematics, trade-offs, and implementation details of different retry approaches.
Why Webhook Retries Matter
Webhooks fail. Network blips, temporary server errors, rate limits, and deployments cause transient failures. Studies show 2-5% of webhook deliveries fail on first attempt, but 90% of those failures are recoverable with proper retry logic.
Without retries, a single network hiccup means lost data: missed notifications, failed payments, broken integrations. A robust retry strategy transforms failures into minor delays instead of data loss.
The challenge: retry too aggressively and you overwhelm struggling endpoints; retry too conservatively and you abandon recovery.
Linear Backoff: The Simple Approach
Linear backoff spaces retries at fixed intervals. The formula is straightforward:
delay = base_interval × attempt_number
For a 60-second base interval:
- Attempt 1: 60 seconds
- Attempt 2: 120 seconds
- Attempt 3: 180 seconds
- Attempt 4: 240 seconds
Implementation Example
def deliver_with_linear_retry(webhook_url: str, payload: dict, max_attempts: int = 5):
for attempt in range(1, max_attempts + 1):
try:
response = requests.post(webhook_url, json=payload, timeout=30)
if response.status_code < 500:
return response
except requests.RequestException:
pass
if attempt < max_attempts:
delay = 60 * attempt
time.sleep(delay)
raise WebhookDeliveryFailed(f"Failed after {max_attempts} attempts")Pros and Cons
Pros:
- Predictable timing, simple to understand
- Minimal code complexity
- Steady retry cadence
Cons:
- Thundering herd: Multiple failures retry in sync, creating load spikes
- Inefficient for outages: Retries at 1, 2, 3, 4 minutes don't help if endpoint is down for hours
- Resource intensive: Many retries needed to span long outages
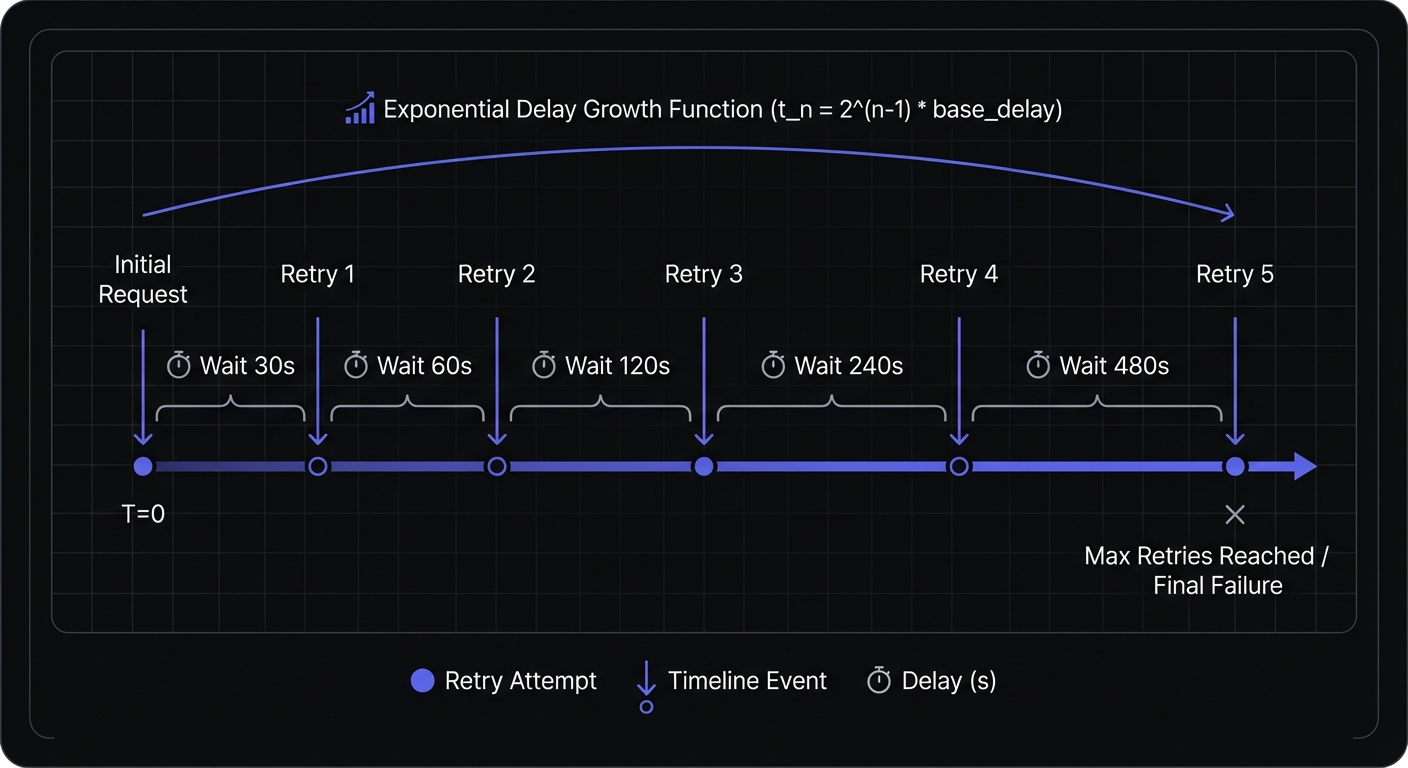
Exponential Backoff: The Industry Standard
Exponential backoff increases delays geometrically, giving struggling systems progressively more time to recover:
delay = base_interval × (2 ^ attempt_number)
For a 30-second base interval:
- Attempt 1: 30 seconds
- Attempt 2: 60 seconds
- Attempt 3: 120 seconds (2 minutes)
- Attempt 4: 240 seconds (4 minutes)
- Attempt 5: 480 seconds (8 minutes)
Implementation Example
def deliver_with_exponential_retry(webhook_url: str, payload: dict, max_attempts: int = 8):
for attempt in range(1, max_attempts + 1):
try:
response = requests.post(webhook_url, json=payload, timeout=30)
if response.status_code < 500:
return response
except requests.RequestException:
pass
if attempt < max_attempts:
delay = 30 * (2 ** attempt)
time.sleep(delay)
raise WebhookDeliveryFailed(f"Failed after {max_attempts} attempts")Pros and Cons
Pros:
- Fewer retries to span long windows
- Respectful to overwhelmed systems
- Naturally adapts to rate limiting
Cons:
- Still synchronizes retries across multiple failures
- Delays can grow without caps
- Predictable patterns visible to load balancers
Exponential Backoff with Jitter: The Best Practice
Adding randomness (jitter) to exponential backoff solves the thundering herd problem by desynchronizing retry attempts:
delay = random(0, base_interval × (2 ^ attempt_number))
Or using "full jitter" (recommended):
delay = random(0, min(max_delay, base_interval × (2 ^ attempt_number)))
Implementation Example
import random
def deliver_with_jittered_retry(webhook_url: str, payload: dict, max_attempts: int = 10):
for attempt in range(1, max_attempts + 1):
try:
response = requests.post(webhook_url, json=payload, timeout=30)
if response.status_code < 500:
return response
except requests.RequestException:
pass
if attempt < max_attempts:
exponential = 30 * (2 ** attempt)
delay = random.randint(0, min(exponential, 3600))
time.sleep(delay)
raise WebhookDeliveryFailed(f"Failed after {max_attempts} attempts")Why Jitter Works
With pure exponential backoff, 1,000 failed webhooks retry at exactly 30s, 60s, 120s, creating load spikes—the "thundering herd" problem.
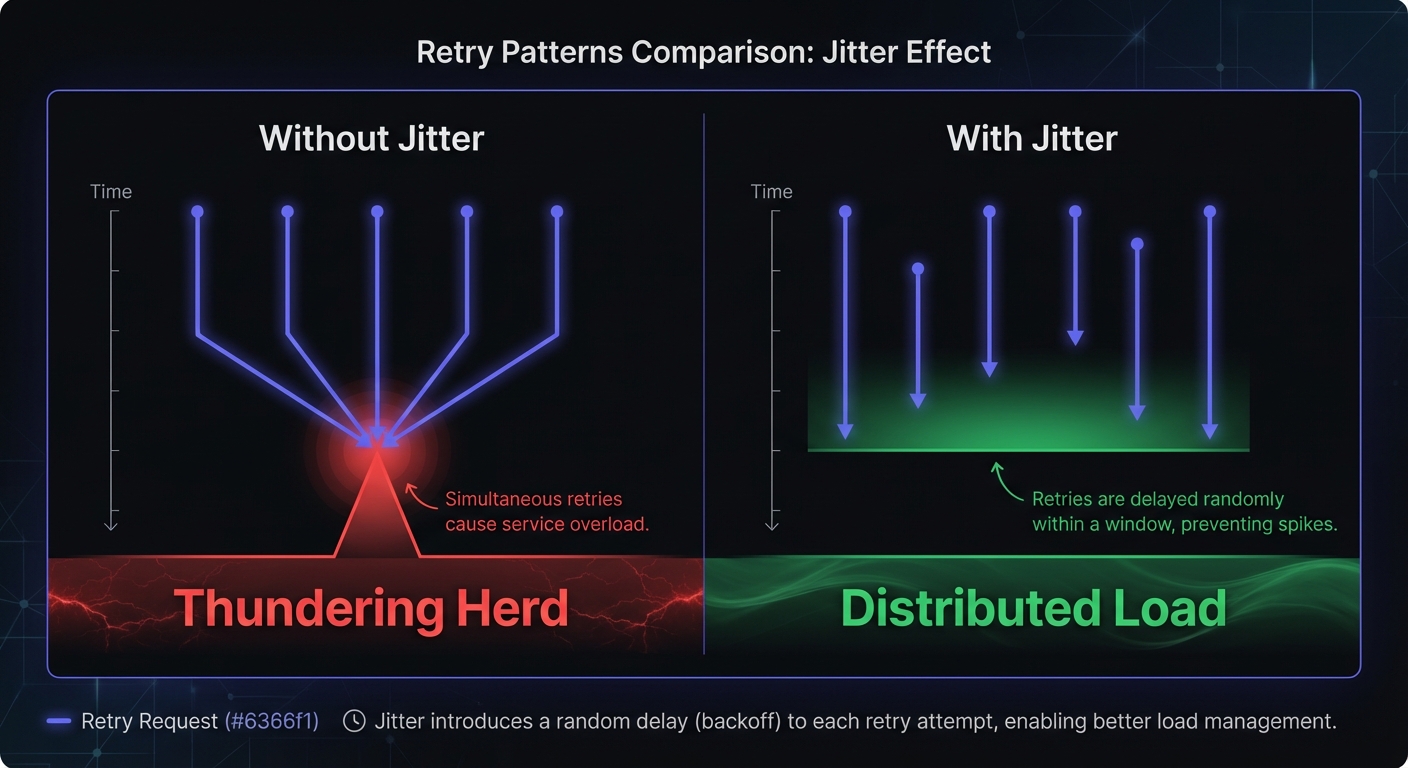
With jitter, those 1,000 retries spread randomly across each interval, producing smooth load instead of synchronized spikes.
Jitter Algorithms
AWS documents three main jitter approaches, each with different trade-offs:
Full Jitter (recommended for most cases):
delay = random.uniform(0, min(max_delay, base * (2 ** attempt)))Uses less work but slightly more time. Best for general use.
Equal Jitter (keeps minimum backoff):
temp = min(max_delay, base * (2 ** attempt))
delay = temp / 2 + random.uniform(0, temp / 2)Always keeps some backoff, preventing very short sleeps. Good when you need guaranteed minimum delays.
Decorrelated Jitter (based on previous delay):
delay = min(max_delay, random.uniform(base, previous_delay * 3))Increases maximum jitter based on previous delay. Can provide better spread in high-contention scenarios.
AWS benchmarks show jittered backoff reduces call count by over 50% compared to un-jittered exponential backoff, with improved completion times.
Hook Mesh uses full jitter by default—the industry standard validated by AWS, Google, and Stripe.
Response Code Handling
Not all failures should trigger retries. Classify response codes to avoid wasting resources on permanent failures.
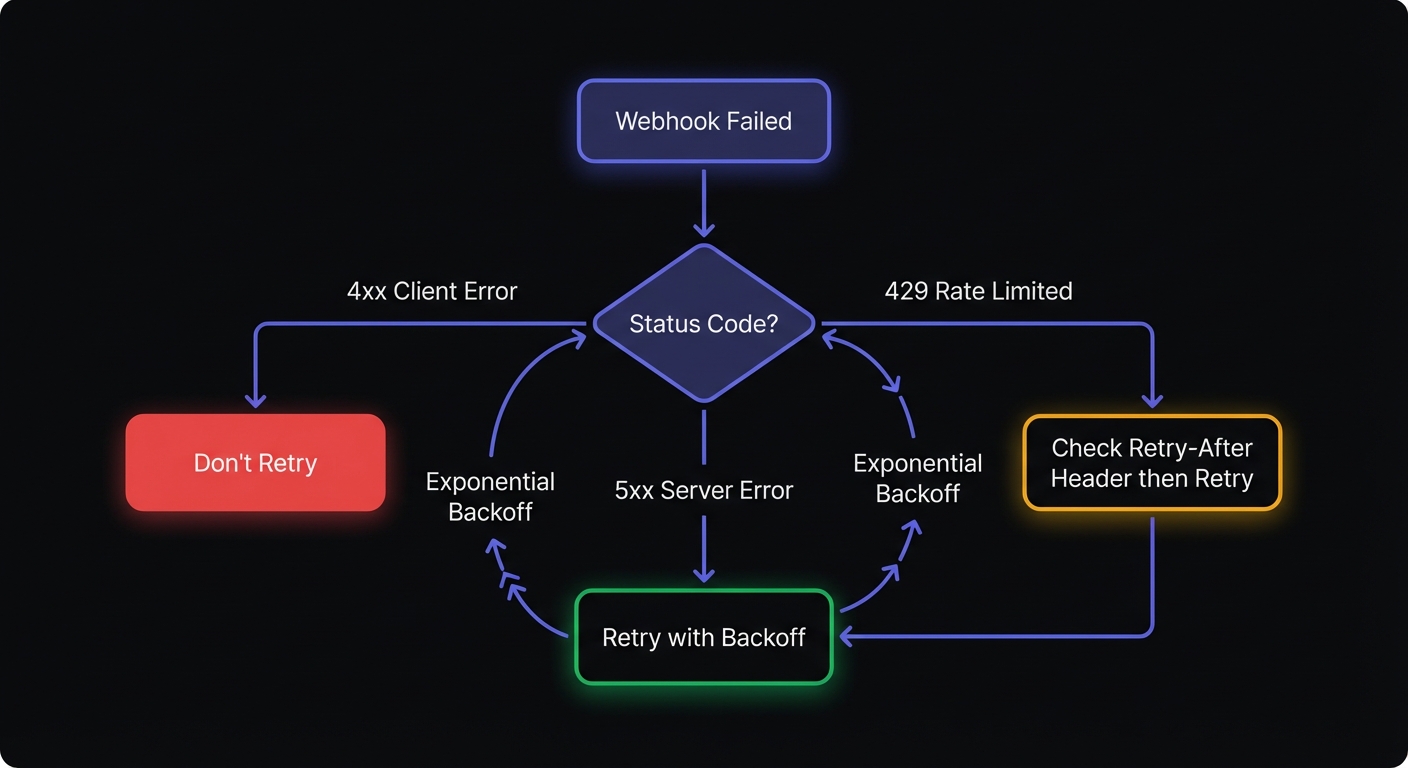
Retryable Errors (5xx)
Server errors indicate temporary issues that may resolve:
| Code | Meaning | Action |
|---|---|---|
| 500 | Internal Server Error | Retry with backoff |
| 502 | Bad Gateway | Retry with backoff |
| 503 | Service Unavailable | Retry with backoff |
| 504 | Gateway Timeout | Retry with backoff |
Non-Retryable Errors (4xx)
Client errors indicate permanent problems that retries won't fix:
| Code | Meaning | Action |
|---|---|---|
| 400 | Bad Request | Don't retry—fix payload |
| 401 | Unauthorized | Don't retry—fix auth |
| 403 | Forbidden | Don't retry—check permissions |
| 404 | Not Found | Don't retry—endpoint removed |
| 422 | Unprocessable Entity | Don't retry—fix payload |
Rate Limiting (429)
The 429 Too Many Requests code requires special handling:
def handle_rate_limit(response):
retry_after = response.headers.get('Retry-After')
if retry_after:
if retry_after.isdigit():
return int(retry_after)
# HTTP-date format
return parse_http_date(retry_after) - time.time()
# Fall back to exponential backoff
return NoneAlways respect Retry-After headers when present. They indicate exactly when the endpoint will accept requests again—ignoring them risks permanent blocking.
Advanced Considerations
Maximum Retry Duration
Every webhook should have a maximum retry window. Common configurations:
- Real-time notifications: 1-4 hours
- Financial transactions: 24-72 hours
- Non-critical updates: 4-8 hours
After the maximum duration, webhooks should move to a dead letter queue for manual review or alternate processing.
Circuit Breakers
When an endpoint fails repeatedly, a circuit breaker can pause all deliveries temporarily:
class CircuitBreaker:
def __init__(self, failure_threshold: int = 5, reset_timeout: int = 300):
self.failures = 0
self.failure_threshold = failure_threshold
self.reset_timeout = reset_timeout
self.last_failure_time = None
self.state = "closed" # closed, open, half-open
def record_failure(self):
self.failures += 1
self.last_failure_time = time.time()
if self.failures >= self.failure_threshold:
self.state = "open"
def can_attempt(self) -> bool:
if self.state == "closed":
return True
if self.state == "open":
if time.time() - self.last_failure_time > self.reset_timeout:
self.state = "half-open"
return True
return False
return True # half-open allows one attemptCircuit breakers prevent wasting resources on endpoints that are clearly down, while automatically recovering when they come back online. For a complete guide to implementing this pattern, see our circuit breaker deep-dive.
Dead Letter Queues
Webhooks that exhaust all retries shouldn't disappear. A dead letter queue preserves failed deliveries for:
- Manual investigation and replay
- Pattern analysis (identifying problematic endpoints)
- Compliance and audit requirements
- Customer support troubleshooting
Configurable Retry Policies
Different customers have different reliability requirements. Allow customization of:
- Maximum attempts: 3-10 depending on criticality
- Maximum duration: 1 hour to 72 hours
- Backoff multiplier: 1.5x, 2x, or 3x growth
- Maximum delay cap: Prevent delays from growing indefinitely
Example configuration interface:
{
"retry_policy": {
"max_attempts": 10,
"max_duration_hours": 24,
"initial_delay_seconds": 30,
"multiplier": 2,
"max_delay_seconds": 3600,
"jitter": true
}
}This flexibility lets customers balance between aggressive recovery (more attempts, shorter windows) and resource efficiency (fewer attempts, longer windows).
Documentation Requirements
One often-overlooked aspect: document your retry behavior explicitly. Users need to know:
- Exact retry schedule: When does each attempt occur?
- Which response codes trigger retries: 5xx only? Timeouts?
- Total retry window: How long until you stop trying?
- Dead letter queue behavior: What happens after exhaustion?
Vague documentation like "we retry failed webhooks" creates integration problems. Specify the exact schedule:
Attempt 1: Immediate
Attempt 2: 30 seconds
Attempt 3: 1 minute
Attempt 4: 2 minutes
Attempt 5: 4 minutes
Attempt 6: 8 minutes
...up to 24 hours maximum
Idempotency Requirements
Retries mean duplicate deliveries. Your webhook consumers must handle this safely through idempotent processing:
def process_webhook(event_id: str, payload: dict):
# Check if already processed
if db.exists(f"processed:{event_id}"):
return {"status": "already_processed"}
# Process the event
result = handle_event(payload)
# Mark as processed
db.set(f"processed:{event_id}", True, ex=86400)
return resultAlways include unique event IDs in webhook payloads. Without idempotency, retries cause duplicate orders, double charges, and repeated notifications.
Real-World Scenarios
Network failures: Brief issues resolve in seconds. Early retries at short intervals handle this.
Rate limiting (429): Exponential backoff naturally reduces pressure. Always respect Retry-After headers.
Endpoint downtime: Hours-long outages require extended retry windows. Exponential backoff spans these efficiently.
Deployments: Brief failures during rollouts resolve quickly. Retries bridge these gaps invisibly.
Cascading failures: When one service fails, dependent services often fail simultaneously. Jitter prevents synchronized recovery attempts from causing secondary failures.
Implementation Checklist
Before shipping retry logic, verify:
- Exponential backoff with jitter (not linear)
- Maximum delay cap to prevent infinite growth
- Response code classification (retry 5xx, skip 4xx)
- Retry-After header handling for 429 responses
- Dead letter queue for exhausted retries
- Idempotency keys in webhook payloads
- Configurable policies per endpoint
- Documented retry schedule for users
- Monitoring and alerting on retry rates
Conclusion
Webhook retry strategies directly impact reliability. Linear backoff is simple but struggles with real-world patterns. Exponential backoff efficiently handles extended outages. Jitter eliminates thundering herd—use full jitter for most cases.
Your configuration depends on use case: financial data warrants longer windows and more attempts; real-time notifications prioritize faster failure detection. Classify response codes correctly: retry server errors, skip client errors, respect rate limits.
Hook Mesh implements exponential backoff with full jitter, configurable retry policies, and automatic dead letter queuing. Look for providers that offer retry visibility and let customers customize their reliability guarantees—these transform webhooks into dependable event-driven infrastructure.
Related Posts
Webhook Circuit Breakers: Protect Your Infrastructure
Learn how to implement the circuit breaker pattern for webhook delivery to prevent cascading failures, handle failing endpoints gracefully, and protect your infrastructure from retry storms.
Webhook Dead Letter Queues: Complete Technical Guide
Learn how to implement dead letter queues (DLQ) for handling permanently failed webhook deliveries. Covers queue setup, failure criteria, alerting, and best practices for webhook reliability.
Webhook Idempotency: Why It Matters and How to Implement It
A comprehensive technical guide to implementing idempotency for webhooks. Learn about idempotency keys, deduplication strategies, and implementation patterns with Node.js and Python code examples.
Build vs Buy: Webhook Infrastructure Decision Guide
A practical guide for engineering teams deciding whether to build webhook delivery infrastructure from scratch or use a managed service. Covers engineering costs, timelines, and when each approach makes sense.
Webhook Observability: Logging, Metrics, and Tracing
A comprehensive technical guide to implementing observability for webhook systems. Learn about structured logging, key metrics to track, distributed tracing with OpenTelemetry, and alerting best practices.