Why You Shouldn't Rely on Webhook Ordering
A deep technical analysis of why webhook ordering guarantees are nearly impossible in distributed systems, and practical patterns for building systems that handle out-of-order delivery gracefully.
Why You Shouldn't Rely on Webhook Ordering
You update a subscription, then cancel it. Your consumer processes the cancellation first, then the update—and the cancelled customer now has an active subscription. This is out-of-order webhook delivery.
Webhook ordering is misunderstood in event-driven architecture. Developers assume sequential events arrive sequentially. They don't. Building systems around this assumption leads to subtle bugs that surface weeks later.
This post explores why ordering is hard, what causes out-of-order delivery, and how to design systems that handle disorder gracefully.
Why Ordering Is Hard: The Distributed Systems Reality
Webhooks operate in a distributed environment where ordering guarantees are extremely difficult—often impossible—to provide. Understanding why requires grasping a few fundamental challenges.
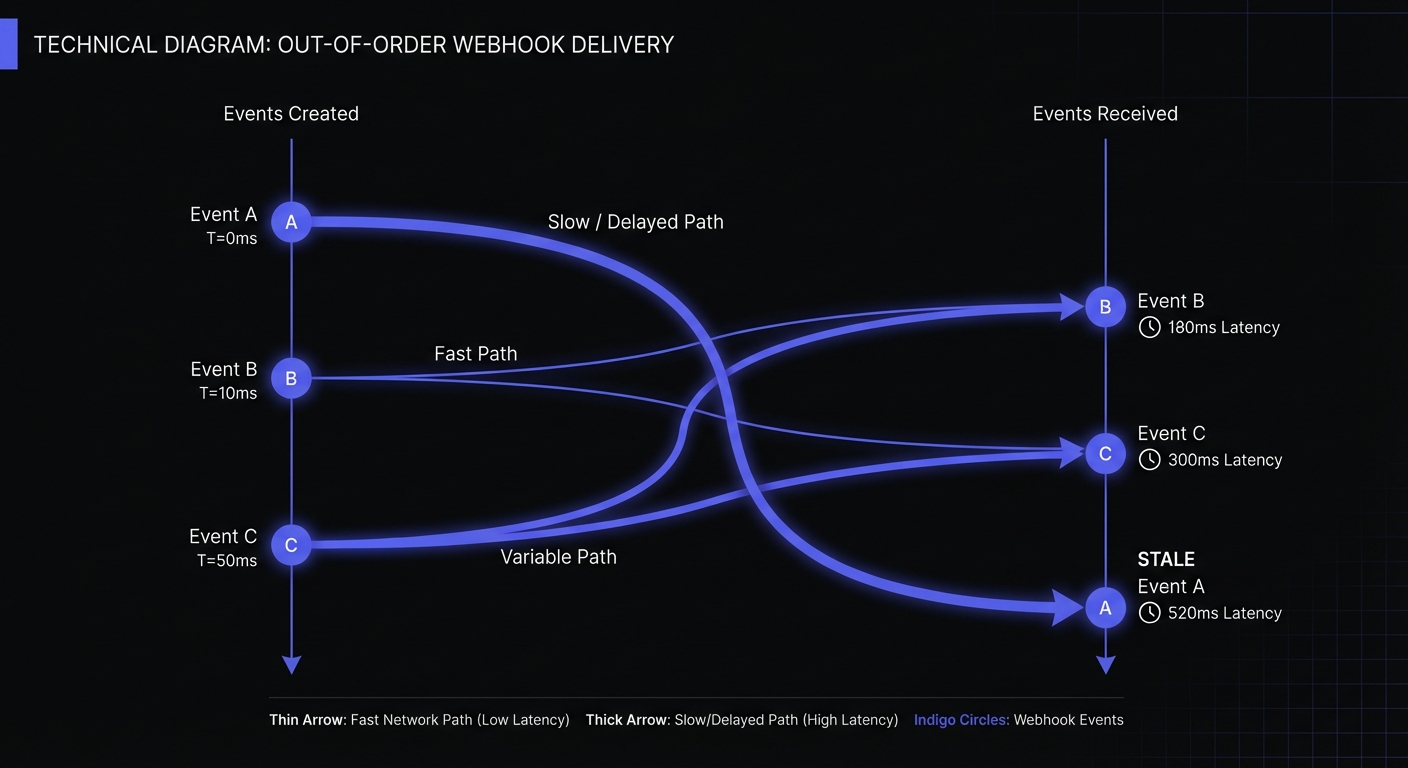
Network unreliability: Two sequential HTTP requests don't arrive sequentially. The first may take a slow path; the second flies through first. Load balancers, CDNs, and geographic distribution worsen this.
Parallel processing for scale: Sequential delivery (wait for completion before next) would require 5,000 seconds to send 10,000 webhooks/sec at 500ms each. Parallel workers are essential but break ordering:
Event A (T=0ms) → Worker 1 → delivers T=520ms
Event B (T=10ms) → Worker 2 → delivers T=180ms
Result: B arrives 340ms before A
Retries destroy order: When first delivery fails and enters a retry queue, subsequent events succeed immediately and arrive first—unavoidable with essential retry mechanisms:
Event 1: Fails → retry in 30s
Event 2: Succeeds → immediate
Event 3: Succeeds → immediate
Event 1: Retry succeeds → 30s late
Arrival order: 2, 3, 1
Why Providers Don't Guarantee Order
Most webhook providers—including Stripe, GitHub, Twilio, and yes, Hook Mesh—explicitly do not guarantee FIFO (first-in, first-out) delivery. This isn't laziness or oversight; it's a deliberate architectural decision.
Guaranteeing order requires:
- Sequential delivery per destination (throughput penalty)
- Head-of-line blocking (one slow endpoint blocks all)
- Complex distributed coordination
- Retry complications (block all or break guarantee)
Trade-off: reliability beats ordering. A system that guarantees order but drops events is less useful than one that guarantees delivery but not order.
Some providers offer ordered delivery for high-value cases with throughput penalties. For general-purpose delivery at scale, assume out-of-order arrival.
How Major Providers Handle Ordering
| Provider | Ordering Guarantee | Metadata Provided |
|---|---|---|
| Stripe | Best-effort, no guarantee | created timestamp, api_version |
| GitHub | No guarantee | X-GitHub-Delivery ID, timestamp |
| Shopify | No guarantee | X-Shopify-Topic, timestamps |
| Twilio | No guarantee | Timestamp header |
| Hook Mesh | Best-effort, optional FIFO | timestamp, sequence_number |
All major providers prioritize at-least-once delivery over strict ordering. Design accordingly.
Real-World Scenarios Where Order Breaks
Understanding specific failure modes helps you design appropriate defenses.
Scenario 1: Rapid State Changes
A user updates their profile three times in quick succession:
T=0ms: user.updated (name: "Alice")
T=50ms: user.updated (name: "Alicia")
T=100ms: user.updated (name: "Ali")
If the first delivery takes 200ms and the others take 50ms each, arrivals could be:
Arrived: user.updated (name: "Alicia")
Arrived: user.updated (name: "Ali")
Arrived: user.updated (name: "Alice") // This is now stale!
Processing these in arrival order leaves the user with the wrong name.
Scenario 2: Create-Then-Update Race
An object is created and immediately modified:
T=0ms: order.created (status: "pending")
T=10ms: order.updated (status: "confirmed")
If the update arrives first, your system might reject it—the order doesn't exist yet. When the create finally arrives, you have an order stuck in "pending" status.
Scenario 3: Retry-Induced Reversal
A subscription is upgraded, then downgraded:
T=0ms: subscription.updated (plan: "pro") → Fails, retries in 60s
T=30s: subscription.updated (plan: "basic") → Succeeds immediately
T=60s: subscription.updated (plan: "pro") → Retry succeeds
The customer downgraded to "basic," but after the retry, your system shows "pro."
How to Handle Out-of-Order Delivery
The solution isn't preventing disorder—it's designing systems that handle it correctly.
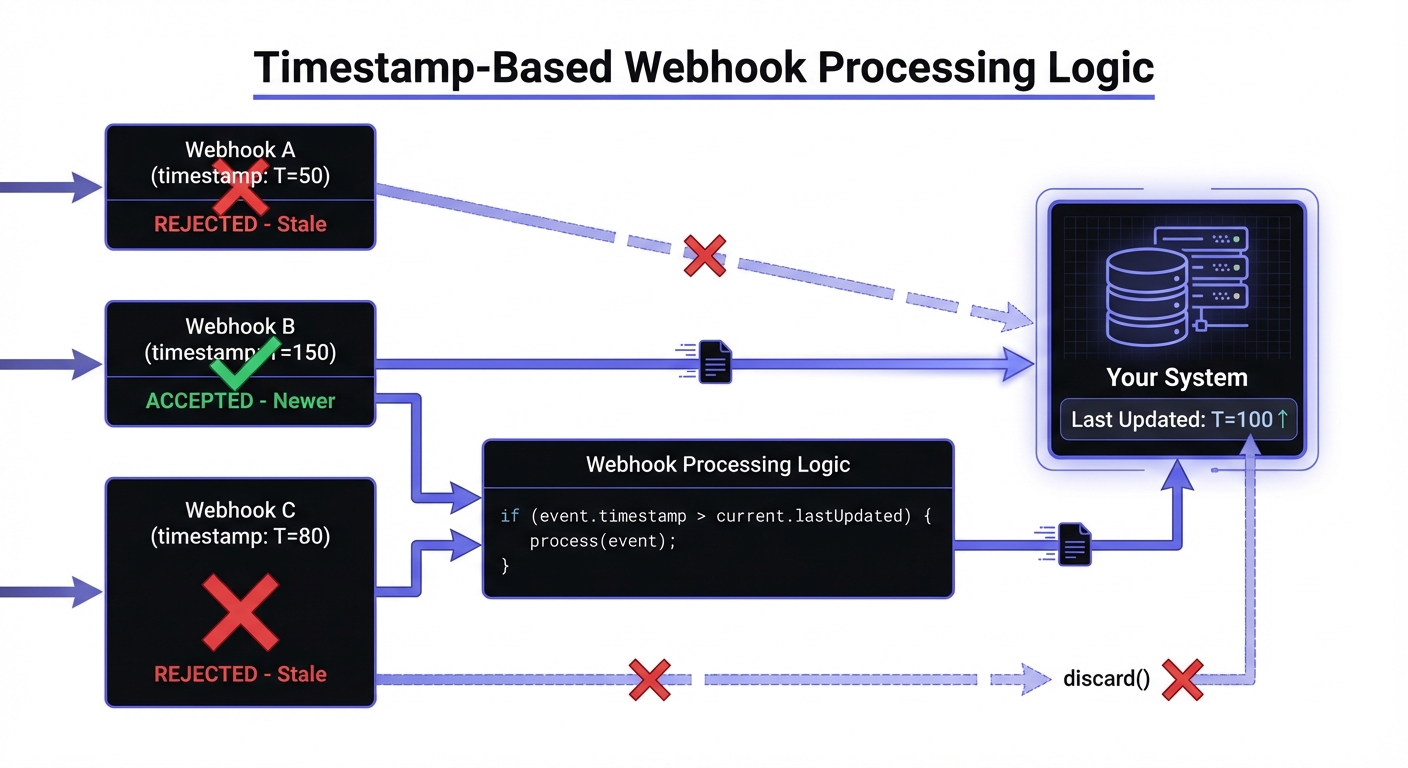
Strategy 1: Timestamp-Based Ordering
Include a timestamp in every webhook payload and only process events newer than your current state.
import datetime
from dataclasses import dataclass
from typing import Optional
@dataclass
class WebhookEvent:
event_type: str
resource_id: str
timestamp: datetime.datetime
data: dict
class OrderProcessor:
def __init__(self, db):
self.db = db
def process_webhook(self, event: WebhookEvent) -> bool:
"""Process webhook only if it's newer than current state."""
current = self.db.get_resource(event.resource_id)
if current and current.last_updated >= event.timestamp:
# Event is stale, acknowledge but don't process
print(f"Skipping stale event: {event.timestamp} <= {current.last_updated}")
return True # Return success to prevent retries
# Event is newer, apply the update
self.db.update_resource(
resource_id=event.resource_id,
data=event.data,
last_updated=event.timestamp
)
return TrueThis approach requires the webhook provider to include reliable timestamps. Most major providers do—check for fields like created_at, timestamp, or occurred_at in the payload.
Strategy 2: Sequence Numbers
Some providers include monotonically increasing sequence numbers. These are more reliable than timestamps because they're immune to clock skew.
async function processWebhook(event) {
const { resourceId, sequenceNumber, data } = event;
const result = await db.query(`
UPDATE resources
SET data = $1, sequence_number = $2
WHERE id = $3
AND (sequence_number IS NULL OR sequence_number < $2)
RETURNING id
`, [data, sequenceNumber, resourceId]);
if (result.rowCount === 0) {
console.log(`Skipping event with sequence ${sequenceNumber} - already processed newer`);
}
// Always return 200 to acknowledge receipt
return { status: 200 };
}The database query atomically checks and updates only if the new sequence number is higher.
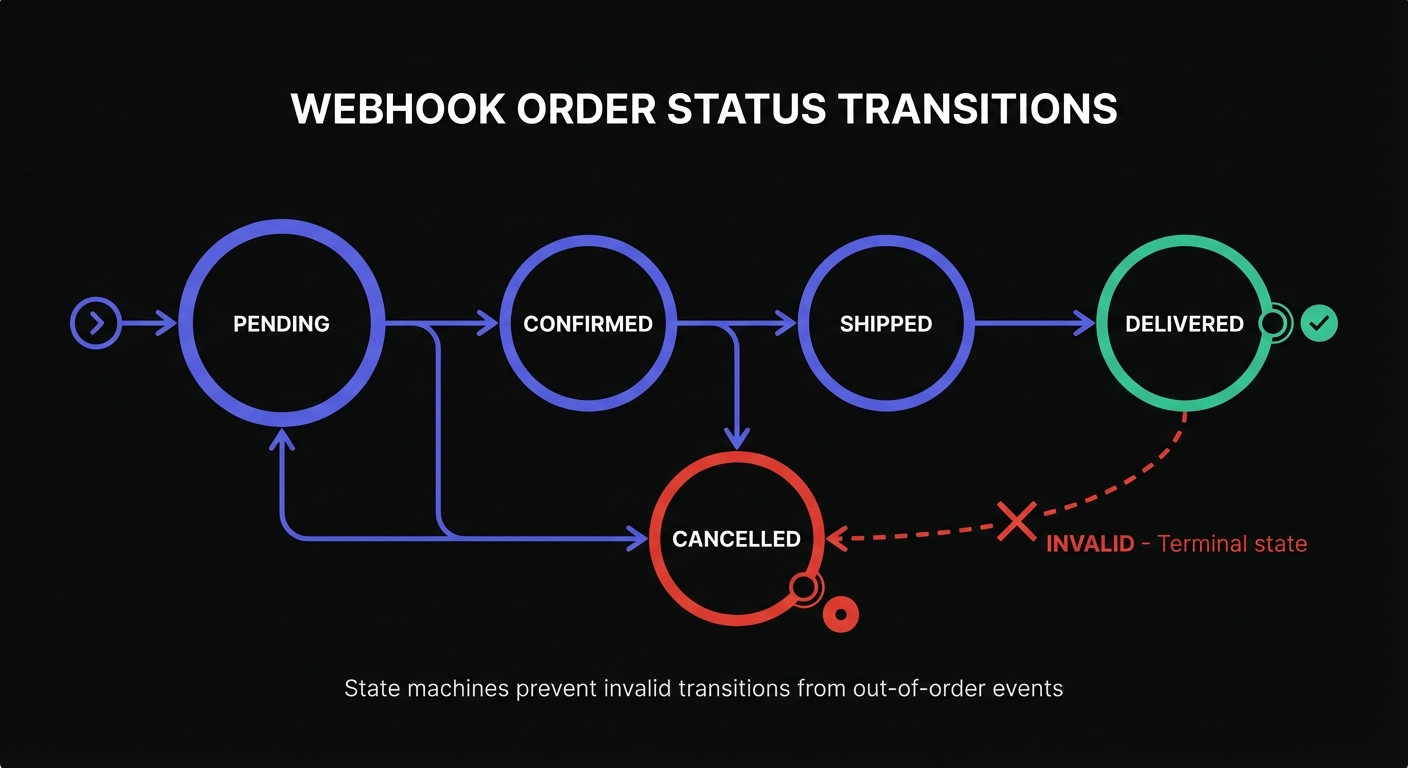
Strategy 3: State Machines
For complex state transitions, model your domain as a state machine with explicit valid transitions. Invalid transitions from out-of-order events get rejected automatically.
from enum import Enum
from typing import Set
class OrderStatus(Enum):
PENDING = "pending"
CONFIRMED = "confirmed"
SHIPPED = "shipped"
DELIVERED = "delivered"
CANCELLED = "cancelled"
VALID_TRANSITIONS: dict[OrderStatus, Set[OrderStatus]] = {
OrderStatus.PENDING: {OrderStatus.CONFIRMED, OrderStatus.CANCELLED},
OrderStatus.CONFIRMED: {OrderStatus.SHIPPED, OrderStatus.CANCELLED},
OrderStatus.SHIPPED: {OrderStatus.DELIVERED},
OrderStatus.DELIVERED: set(), # Terminal state
OrderStatus.CANCELLED: set(), # Terminal state
}
def process_order_webhook(order_id: str, new_status: OrderStatus, timestamp: datetime):
order = db.get_order(order_id)
if order is None:
if new_status == OrderStatus.PENDING:
db.create_order(order_id, new_status, timestamp)
else:
# Non-creation event for unknown order - queue for later
queue_for_retry(order_id, new_status, timestamp)
return
# Check if transition is valid
if new_status not in VALID_TRANSITIONS[order.status]:
# Invalid transition - might be out of order or duplicate
if timestamp <= order.last_updated:
return # Stale event, ignore
# Log for investigation - might indicate a bug
log_invalid_transition(order, new_status, timestamp)
return
db.update_order(order_id, new_status, timestamp)Design Patterns for Disorder
Thin Payloads
Design webhooks with minimal data—just enough to identify what changed. Consumers fetch current state via API.
// Thin payload - ordering doesn't matter
{
"event": "order.updated",
"order_id": "ord_123",
"changed_fields": ["status", "shipping_address"],
"timestamp": "2026-01-20T10:30:00Z"
}
// vs. Fat payload - ordering critical
{
"event": "order.updated",
"order_id": "ord_123",
"data": {
"status": "shipped",
"shipping_address": { ... },
"items": [ ... ]
}
}With thin payloads, out-of-order delivery becomes irrelevant—the consumer always fetches the current state before acting. This shifts ordering responsibility from the delivery system to the consumer's API call.
Event Sourcing
Store events as source of truth. Replay in correct order when needed.
def append_event(resource_id: str, event: dict):
"""Append event to log regardless of order."""
db.insert_event(
resource_id=resource_id,
event_type=event["type"],
timestamp=event["timestamp"],
payload=event
)
def rebuild_state(resource_id: str) -> dict:
"""Rebuild current state by replaying events in timestamp order."""
events = db.get_events(resource_id, order_by="timestamp")
state = {}
for event in events:
state = apply_event(state, event)
return stateIdempotent Operations
Design every handler safely callable multiple times. See webhook idempotency for patterns.
def process_payment_webhook(event: dict):
event_id = event["id"]
# Check if already processed
if db.event_exists(event_id):
return {"status": "already_processed"}
# Process with idempotency key
try:
with db.transaction():
db.record_event(event_id)
apply_payment(event["data"])
except UniqueViolation:
# Race condition - another worker processed it
return {"status": "already_processed"}
return {"status": "processed"}Version Vectors
For complex multi-field updates, track versions per field rather than per resource. This allows different fields to be updated independently while still maintaining consistency—each field only accepts updates with a higher version number than what's currently stored.
Fetch Before Process Pattern
Treat webhooks as signals, not data sources. When you receive an event, fetch the current state from the provider's API before processing.
async function handleWebhook(event) {
const { resourceType, resourceId } = event;
// Don't trust webhook payload for state - fetch current
const currentState = await api.fetch(`/${resourceType}/${resourceId}`);
// Process with guaranteed-fresh data
await processResource(currentState);
return { status: 200 };
}This pattern eliminates ordering concerns entirely—you always work with the latest state. Trade-off: additional API calls and potential rate limiting during high-volume bursts.
Queue and Reorder on Receive
Queue webhooks internally rather than processing immediately. This gives you control over processing order and lets you handle bursts gracefully.
def webhook_handler(event: dict):
# Validate signature quickly
if not verify_signature(event):
return {"status": 401}
# Queue for async processing - don't block
queue.enqueue(
resource_id=event["resource_id"],
timestamp=event["timestamp"],
payload=event
)
# Acknowledge immediately
return {"status": 200}
def process_queue():
"""Background worker processes queued events in timestamp order."""
events = queue.get_pending(order_by="timestamp")
for event in events:
process_event(event)Most ordering problems disappear when you control the processing queue. The receiver can sort by timestamp before processing.
FIFO Delivery: When Providers Offer It
Some providers (including Svix) offer optional FIFO (first-in, first-out) endpoints for use cases requiring strict ordering. Trade-offs to understand:
| Aspect | Best-Effort (Default) | FIFO Delivery |
|---|---|---|
| Throughput | High (parallel) | Limited (~20/sec due to acknowledgment waits) |
| Failed delivery | Continues to next | Blocks until success or disabled |
| Use case | Most webhooks | Financial transactions, audit logs |
| Recovery | Automatic | Manual intervention may be required |
FIFO delivery works by batching events and waiting for acknowledgment before sending the next batch. A single slow or failing endpoint blocks all subsequent deliveries to that destination.
When to use FIFO: Regulatory requirements, financial audit trails, or state machines where gaps cause system failures.
When to avoid FIFO: High-volume events, non-critical notifications, or any case where temporary disorder is acceptable.
Practical Advice: Design for Disorder
Treat webhooks as untrusted distributed queues. They're replayable, unordered, and duplicated. Once you internalize this, handling them becomes straightforward.
Don't depend on order—ever. Providers claiming ordered delivery will eventually break (network issues, bugs, edge cases).
Acknowledge fast, process later. Return 200 within 1-2 seconds. Queue the event internally and process asynchronously. Slow handlers trigger retries, creating more disorder.
# Good: Fast acknowledgment
def handler(event):
queue.enqueue(event)
return {"status": 200} # Return immediately
# Bad: Slow processing blocks
def handler(event):
process_complex_business_logic(event) # 5 seconds
return {"status": 200} # Triggers retry before reaching hereInclude ordering metadata: Timestamps and sequence numbers help consumers handle disorder. If you're sending webhooks, always include timestamp and consider adding sequence_number per resource.
Make handlers idempotent: Every handler should produce the same result whether called once or ten times. Use event IDs for deduplication. See webhook idempotency patterns.
Reject invalid transitions, rely on retries. If a card.created webhook references a customer that doesn't exist yet, reject it (return 4xx). The provider will retry, and by then customer.created will have arrived. Webhooks are eventually consistent.
Test with disorder: Deliberately deliver out of order. Shuffle sequences. Duplicate events. Your system should handle this gracefully.
Monitor for anomalies: Track stale events, out-of-order arrivals, processing conflicts. Spikes indicate upstream issues. Webhook observability makes these visible.
Conclusion
Webhook ordering is a distributed systems problem with no perfect solution. Reliable delivery beats strict ordering—this is why Stripe, GitHub, Shopify, and Hook Mesh all prioritize at-least-once delivery over FIFO guarantees.
You don't need ordering guarantees. Design systems handling out-of-order delivery using:
- Timestamps for freshness checks
- Sequence numbers for atomic updates
- State machines for transition validation
- Thin payloads with fetch-before-process
- Idempotent operations for safe reprocessing
Build resilient integrations that work regardless of arrival order. Test with deliberate disorder. Monitor for anomalies with proper webhook observability.
Hook Mesh includes timestamps and optional sequence numbers on every webhook, plus retry strategies that help you debug production issues when disorder does cause problems. When evaluating webhook solutions, understanding these ordering complexities helps inform your build vs buy decision.
Related Posts
Webhook Idempotency: Why It Matters and How to Implement It
A comprehensive technical guide to implementing idempotency for webhooks. Learn about idempotency keys, deduplication strategies, and implementation patterns with Node.js and Python code examples.
Webhook Retry Strategies: Linear vs Exponential Backoff
A technical deep-dive into webhook retry strategies, comparing linear and exponential backoff approaches, with code examples and best practices for building reliable webhook delivery systems.
Webhook Observability: Logging, Metrics, and Tracing
A comprehensive technical guide to implementing observability for webhook systems. Learn about structured logging, key metrics to track, distributed tracing with OpenTelemetry, and alerting best practices.
Debugging Webhooks in Production: A Systematic Approach
Learn how to debug webhook issues in production with a systematic approach covering signature failures, timeouts, parsing errors, and more. Includes practical tools, real examples, and step-by-step checklists.
Build vs Buy: Webhook Infrastructure Decision Guide
A practical guide for engineering teams deciding whether to build webhook delivery infrastructure from scratch or use a managed service. Covers engineering costs, timelines, and when each approach makes sense.