Build vs Buy: Webhook Infrastructure Decision Guide
A practical guide for engineering teams deciding whether to build webhook delivery infrastructure from scratch or use a managed service. Covers engineering costs, timelines, and when each approach makes sense.

Build vs Buy: Should You Build Webhook Infrastructure In-House?
Every growing SaaS company faces the same question: build webhook infrastructure ourselves or use a managed service?
Webhooks seem simple—they're just HTTP POSTs. But as GitHub, Segment, and Square discovered, webhook delivery is a distributed systems problem. GitHub's 2018 outage permanently lost 200,000 payloads. Segment spent 9 months building Centrifuge after discovering traditional queues couldn't handle their scale.
This post breaks down what building entails, realistic costs and timelines, and whether building or buying makes sense.
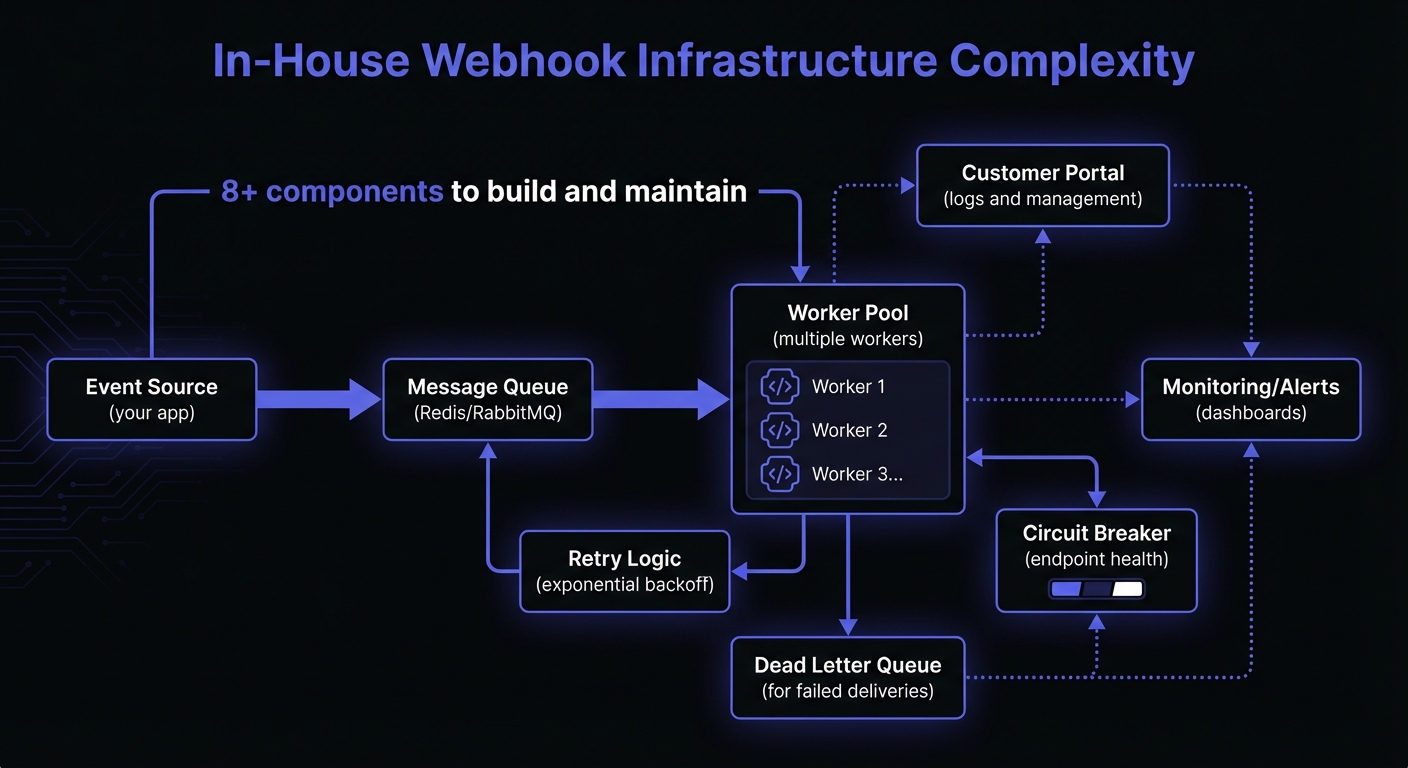
What Building Webhook Infrastructure Actually Involves
Production-ready webhook delivery requires solving multiple interconnected problems.
Retry Logic and Backoff Strategies
Webhooks fail constantly: endpoints down, network timeouts, rate limits. Production systems need intelligent exponential backoff and jitter to avoid thundering herds.
Segment discovered: 1.5% of data succeeds on retry, 50% between 3rd-10th attempts. Retry strategy needs hours or days, not minutes. Stripe: 3 days. Square: 72 hours. PayPal: 25 attempts over 3 days.
Requires: retry queues, configurable backoff, attempt limits, dead-letter queues.
Circuit Breakers for Failing Endpoints
Dead endpoints cause endless retries, clogging queues and delaying other deliveries. Convoy's circuit breaker reduced failed attempts from 100K/day to 5K (95% improvement). Building a distributed circuit breaker requires shared state (Redis), leader election, and configured thresholds.
Signature Verification and Security
Every webhook must be cryptographically signed for authenticity. Svix cataloged 9 common failure modes: weak primitives, shared secrets, no replay protection, no zero-downtime rotation.
Proper implementation requires: HMAC-SHA256 with per-endpoint secrets (24+ bytes), signed timestamps, message IDs, secret prefixes, and multi-signature rotation support.
Customer-Facing Portal
Customers need: endpoint management (add/update/disable/delete), delivery logs with full request/response visibility, filtering by event type and status, manual replay, and health indicators.
Monitoring and Observability
Requires: queue depth, event age, latency at p95, success rates by endpoint, dead-letter queue alerts. Also need customer-facing analytics: success rates, latency, volume trends.
Scaling Challenges
Problems compound at scale: slow endpoints create backpressure, large customer batches block small ones, outages spike traffic 10-100x, misbehaving endpoints break pipelines.
Segment discovered every conventional queue fails at scale in unique ways. Solution: use relational database as "virtual queue" instead of message broker. They reached 2M HTTP requests/second after extensive iteration.
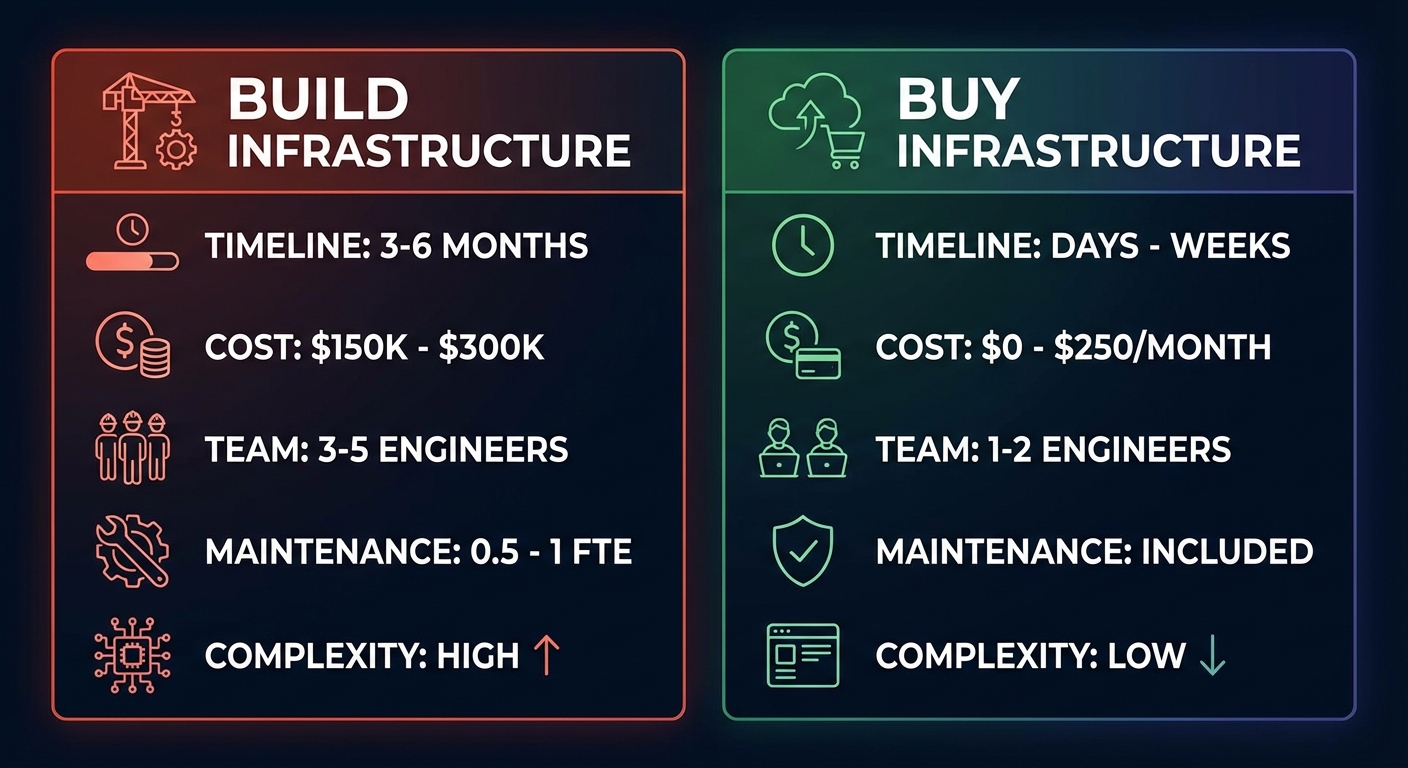
Realistic Engineering Costs and Timeline
Timeline: 3-6 months for initial release (assumes distributed systems experience)
Month 1: architecture and basic delivery. Months 2-3: retries, circuit breakers, dead-letter queues. Months 4-6: portal, monitoring, hardening.
Ongoing maintenance: 0.5-1 FTE not a "build once and forget" system
Hidden costs:
- Infrastructure (queues, databases, workers, monitoring)
- On-call burden
- Opportunity cost vs core product
- Security audits for crypto
- Documentation and SDKs
One engineering manager at Guesty called it "a nightmare" and "personal source of pain." Common sentiment among teams that underestimated complexity.
Impact on Engineering Velocity
Custom webhook infrastructure creates drag beyond direct costs. Teams report:
- Deployment frequency drops from multiple times per day to a few times per week as webhook changes require extra testing
- Lead time increases as simple changes that should take hours now take days when they touch webhook infrastructure
- Change failure rates creep from 10% toward 25% as webhook-related issues become common rollback sources
- Recovery time stretches from sub-hour to 2-4 hours when failures require diving into multiple services
When your team spends 40% of their time on webhook infrastructure, that's 40% not spent on CI/CD improvements, developer tooling, or core product features.
Build vs Buy: Comparison Table
| Factor | Build In-House | Buy (Managed Service) |
|---|---|---|
| Initial timeline | 3-6 months | Days to weeks |
| Upfront cost | $150K-300K in engineering time | $0-250/month typically |
| Ongoing maintenance | 0.5-1 FTE dedicated | Included in subscription |
| Retry logic | Must implement and tune | Battle-tested out of the box |
| Circuit breakers | Must implement distributed solution | Pre-built and configurable |
| Customer portal | Must design and build UI | Embeddable component included |
| Signature verification | Must implement correctly (9+ failure modes) | Industry-standard implementation |
| Scaling | Your responsibility | Provider's responsibility |
| Monitoring/alerting | Must build dashboards | Pre-built analytics |
| SDKs | Must build and maintain | Multiple languages included |
| Time to first webhook | Months | Hours |
When Building In-House Makes Sense
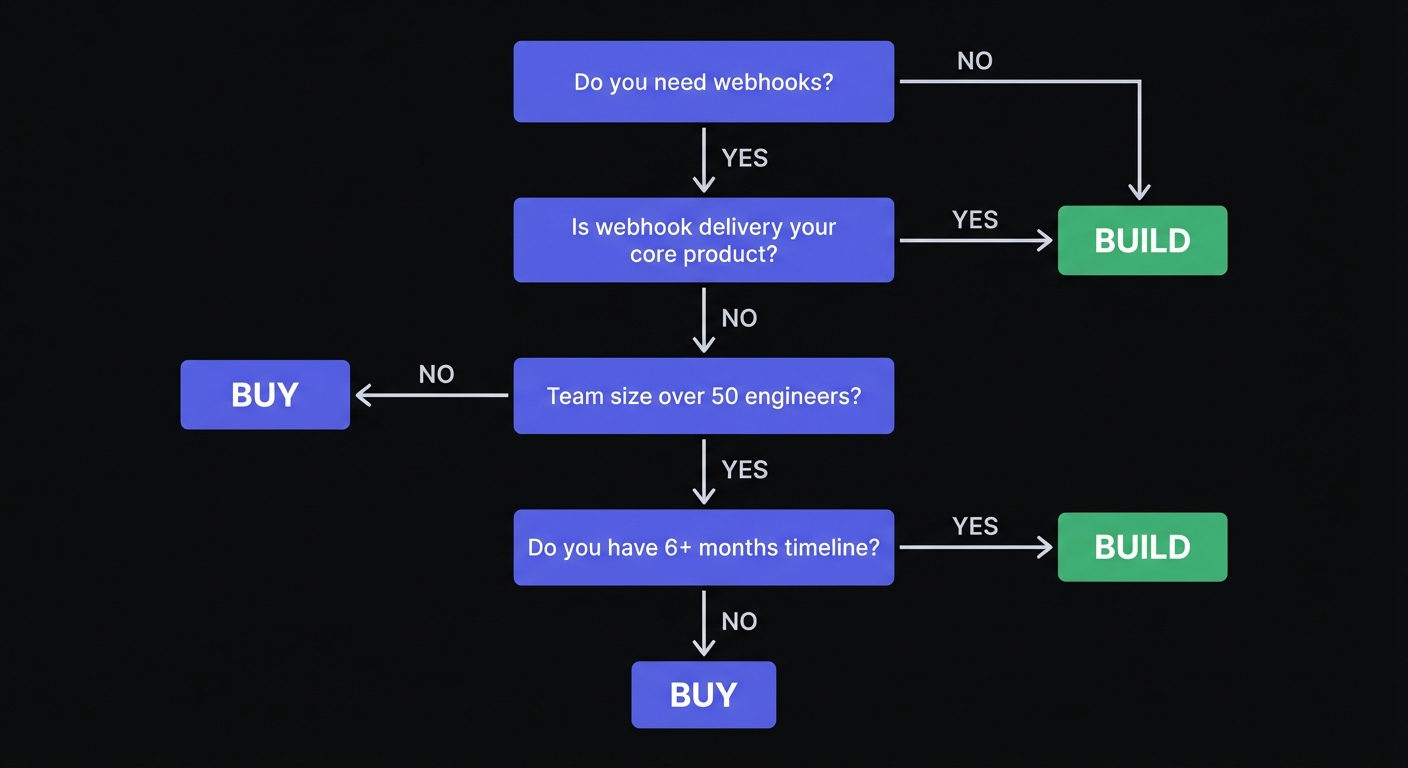
Webhooks are your core product - you need in-house expertise for competitive advantage. Companies like Stripe and Shopify built because webhook delivery is central to their value proposition.
Very custom requirements - unique constraints no provider supports (specialized compliance, proprietary integrations, unusual delivery semantics)
Large, experienced distributed systems team - 50+ engineers with dedicated platform groups can absorb this complexity without impacting product velocity
Massive scale with long time horizon - at Segment-level scale (hundreds of thousands events/second), provider per-event costs become prohibitive. Large enterprises with substantial engineering resources and multi-year horizons sometimes find building economically reasonable.
Strict data residency requirements - if events can never leave your infrastructure and no provider supports your specific requirements
When Buying Makes Sense
Time to market matters - customers asking for webhooks today; 3-6 months building = lost opportunity. Managed services get you from zero to production in days.
Small team - teams under 20 people can't build and maintain without sacrificing product. True cost often exceeds estimates by 3-5x.
Not your differentiator - webhook delivery is table stakes, not competitive advantage. Customers care it works, not how.
Focus on core product - every hour on retries is an hour not on differentiating features. One team estimated achieving feature parity with a managed service would take at least a year of internal development.
Need proven reliability - managed services already solved edge cases and outages. Top providers offer 99.99-99.999% uptime SLAs with battle-tested retry patterns, observability, and multi-region delivery.
Budget constraints - buying often delivers 48% reduction in 5-year operating costs compared to DIY solutions that show hockey-stick cost curves
The Hybrid Approach
The decision isn't always binary. The most common pragmatic pattern: use managed delivery as the backbone while building bespoke business logic on top.
Hybrid works when:
- You need specific payload transformations before delivery
- Custom routing logic based on internal business rules
- Edge filtering to reduce costs on high-volume events
- Thin adapter layer isolating business logic from delivery mechanism
This approach lets you avoid vendor lock-in while gaining reliability benefits. Build a thin integration layer that handles your unique requirements while the managed service handles the hard distributed systems problems.
Open Source: A Middle Ground?
Open source options like Convoy provide self-hosted webhook delivery with professional features. Considerations:
Advantages: Full control, no per-event pricing, data never leaves your infrastructure, ability to customize internals
Challenges: Still requires operational expertise, you own the uptime, scaling and multi-region deployment are your responsibility, security patches require manual updates
Open source makes sense for teams with infrastructure expertise who want ownership without building from scratch. It's not "free"—budget 0.25-0.5 FTE for operations.
Making the Decision for Your Team
Ask these questions:
- How many months of engineering time can we allocate to webhook infrastructure?
- Do we have distributed systems expertise in-house?
- Is webhook delivery a competitive differentiator?
- What's the cost of delayed time to market?
- Who's on-call when the system breaks at 3 AM?
- Do we need data residency that rules out managed services?
For most teams, answers point toward buying. 3-6 months of engineering typically costs $150K-300K alone. Managed service costs a fraction and works immediately. Use webhook provider checklist to compare options systematically.
How Hook Mesh Fits
Hook Mesh handles retries, circuit breakers, signature verification, and scaling. Free tier for getting started, scales predictably for SMB budgets. Battle-tested infrastructure, SDKs in major languages, embeddable portal, full visibility.
The question isn't whether you can build—it's whether you should, given everything else competing for your engineering time.
Ready to add webhooks to your product without the infrastructure headache? Start free with Hook Mesh and send your first webhook in minutes.
Related Posts
The True Cost of Building Webhooks In-House
A detailed breakdown of what it really costs to build, maintain, and scale webhook infrastructure internally. Engineering time, infrastructure expenses, hidden costs, and opportunity cost compared to using a managed service.
Choosing a Webhook Provider: A Checklist for Startup CTOs
A comprehensive evaluation checklist for technical leaders choosing a webhook provider. Covers reliability, security, developer experience, pricing, and the red flags to avoid.
Webhooks for Startups: A Practical Guide
A comprehensive guide for startup founders and engineers on implementing webhooks - when to add them, what to build first, and how to scale without over-engineering.
Webhook Pricing Explained: What Startups Need to Know
A transparent guide to webhook service pricing models. Learn about per-message fees, tiered subscriptions, hidden costs, and how to estimate your true webhook infrastructure spend.
Webhooks for Startups: From MVP to Scale
The definitive guide for startup founders and engineers on implementing webhooks - from your first integration to handling millions of events. Learn when to add webhooks, how to scope your MVP, avoid common pitfalls, and scale confidently.