Webhook Reliability Engineering: The Complete Guide
Master the art of building reliable webhook infrastructure. Learn retry strategies, circuit breakers, rate limiting, failure handling, and observability patterns used by engineering teams at scale.
Webhook Reliability Engineering: The Complete Guide
Webhooks are critical infrastructure—missed payments, dropped notifications, and broken CI/CD pipelines all trace back to webhook failures. Yet webhook reliability remains underestimated.
This guide covers everything needed to build webhook infrastructure your team and customers can depend on.
Table of Contents
- Why Webhook Reliability Matters
- Retry Strategies
- Circuit Breakers
- Rate Limiting
- Handling Failures
- Idempotency and Ordering
- Observability
- Scaling Your Infrastructure
- Build vs Buy
- Conclusion
Why Webhook Reliability Matters
Webhook failures have real consequences: missed payments mean revenue leakage, dropped deployment notifications break CI/CD pipelines, undelivered inventory updates cause overselling.
The problem: webhooks traverse networks you don't control. Your HTTP request must reach a third-party server—potentially overloaded or misconfigured—and return successfully within a timeout window. When sending millions per day, "rare" failures happen constantly.
Webhook reliability requires assuming failure is default and designing every component for resilience. The patterns here help you build infrastructure that gracefully handles distributed systems chaos.
Production Benchmarks
Industry standards from major webhook providers:
| Parameter | Typical Range | Real-World Examples |
|---|---|---|
| Request Timeout | 5-30 seconds | Stripe: 30s, Shopify: 10s, GitHub: 10s |
| Retry Window | 24-72 hours | Stripe: 3 days, Shopify: 48h, Twilio: 24h |
| Retry Attempts | 5-15 attempts | Most providers: 5-8 attempts |
| Circuit Breaker Threshold | 50-70% failure rate | Measured over 10-20 requests |
These benchmarks represent battle-tested defaults that balance delivery reliability against resource consumption. Use them as starting points, then tune based on your specific requirements.
Retry Strategies
Automatic retries are fundamental. When delivery fails, retry with intelligent backoff.
Exponential backoff significantly impacts success rates and system load—it adapts to prolonged outages by spacing retries further apart, reducing load on struggling endpoints. Add jitter (±20% randomness) to prevent the "thundering herd" problem where thousands of retries hit a recovering server simultaneously.
Concrete Retry Schedule
Production retry schedule with exponential backoff (5x multiplier) and jitter:
| Attempt | Base Backoff | With Jitter (+/-20%) |
|---|---|---|
| 1 | 5s | 4-6s |
| 2 | 25s | 20-30s |
| 3 | 125s (~2 min) | 100-150s |
| 4 | 625s (~10 min) | 500-750s |
| 5 | 3,125s (~52 min) | 42-62 min |
| 6 | 15,625s (~4.3 hr) | 3.5-5.2 hr |
| 7+ | Capped at 6 hr | 4.8-7.2 hr |
Aggressive early retries handle transient failures; backing off handles sustained outages. The 6-hour cap prevents indefinitely long delays while allowing multiple daily retry attempts.
Multi-Stage Retry Lifecycle

Production systems implement a four-stage retry pipeline:
Stage 1: Immediate Retries (0-3 attempts, <1 minute apart) Quick retries resolve most transient failures without significant delay.
Stage 2: Backoff Retries (4-10 attempts, exponential spacing) Handles longer outages like deployments, maintenance windows, or rate limiting cool-downs.
Stage 3: Long-Term Queue (hourly attempts for 24-72 hours) Hourly attempts give endpoints time to recover while minimizing wasted resources.
Stage 4: Dead Letter Queue Webhooks land in DLQ after exhausting retries. Preserved for debugging, manual replay, or alerts.
Deep dive: Webhook Retry Strategies: Linear vs Exponential Backoff
Error Classification
Not all errors deserve the same treatment. Your webhook system needs to classify responses and take appropriate action based on the error type. Here's how to handle each category:
| Response | Category | Action |
|---|---|---|
| 2xx | Success | Mark delivered, no further action |
| 400, 422 | Client error (bad payload) | Send to DLQ immediately—retries won't help |
| 401, 403 | Authentication error | Alert operations + DLQ (likely config issue) |
| 404 | Endpoint not found | DLQ + consider disabling endpoint |
| 429 | Rate limited | Retry with Retry-After header if present |
| 500, 502, 503 | Server error | Retry with exponential backoff |
| Timeout | Network/overload | Retry with backoff (may indicate slow endpoint) |
4xx client errors shouldn't be retried—wrong payloads or authentication won't improve on retry. However, 429 (rate limited) and 5xx errors are transient and should retry.
Some edge cases require special handling:
- 401/403 after previously working: The endpoint's credentials may have rotated. Alert the customer rather than silently retrying.
- Repeated 404s: The webhook URL was likely removed. After multiple 404s, disable the endpoint and notify the customer.
- Connection refused: Different from timeouts—usually means the server is down entirely. Apply standard backoff.
Circuit Breakers
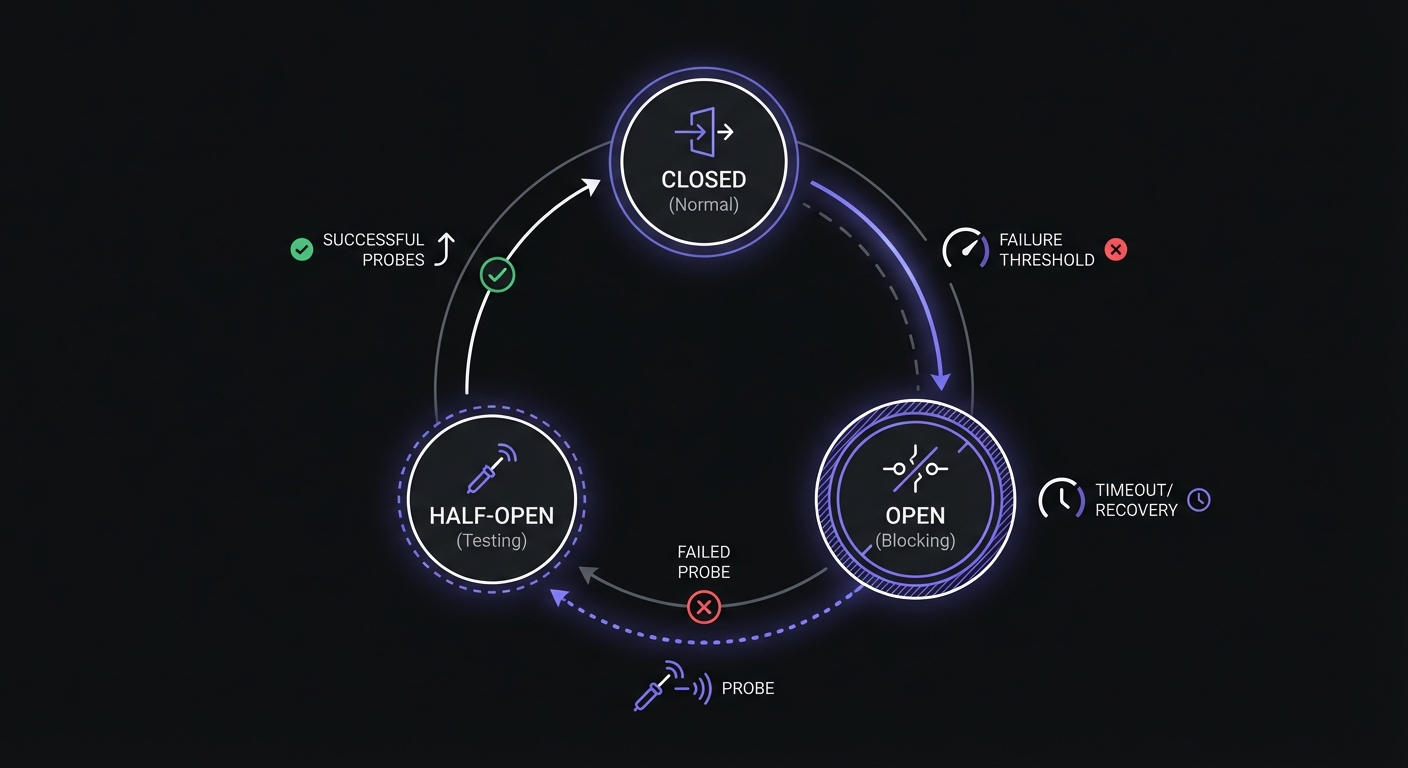
Retries alone worsen outages by hammering failing endpoints. Circuit breakers prevent cascade failures by stopping requests when failure rates spike.
A circuit breaker monitors endpoint health and "trips" when failures exceed a threshold, stopping requests for a cooldown period. After cooldown, it enters half-open state, allowing test requests to probe recovery.
Tuning matters: trip too eagerly and you stop delivery during minor hiccups; too slowly and you waste resources while accumulating backlogs. Thresholds depend on SLAs, webhook criticality, and observed failure patterns.
Deep dive: Implementing Circuit Breakers for Webhook Delivery
Rate Limiting
Rate limiting protects infrastructure and ensures fairness. Protect consumers from traffic spikes while preventing one misbehaving endpoint from starving others.
Operate at three levels: global limits protect infrastructure, per-customer limits ensure fair allocation, per-endpoint limits respect capacity constraints.
Token bucket is the preferred algorithm—it handles bursty traffic while enforcing average rate constraints, allowing brief bursts when capacity is available while throttling sustained high-volume senders.
Deep dive: Webhook Rate Limiting Strategies for High-Volume Delivery
Handling Failures
Some webhooks fail permanently—decommissioned endpoints, bugs rejecting payloads, etc. You need a strategy for terminal failures.
Dead letter queues (DLQs) preserve failed messages for analysis and reprocessing instead of discarding them, preventing blocks on healthy webhooks. Include metadata about failure reasons for easier debugging.
Efficient debugging requires visibility into the full delivery lifecycle: original event, all attempts, response bodies, timing, and states of circuit breakers and rate limiters.
Deep dive: Dead Letter Queues for Webhook Failure Recovery | Debugging Webhooks in Production
Idempotency and Ordering
Reliable delivery introduces duplicate delivery: when a timeout occurs after processing but before your system receives acknowledgment, retry delivers twice. Without handling, this causes double-charges, duplicate notifications, or corruption.
Idempotency keys give each webhook a unique identifier for deduplication. Requires coordination between sender and receiver, clear guarantees, and careful consideration of key lifetime and storage.
Message ordering is equally critical. Retries, parallel processing, and network variability cause out-of-order arrival. For some types order doesn't matter; for status update sequences, order is essential. Understanding when it matters and how to guarantee it is critical for reliability.
Deep dive: The Complete Guide to Webhook Idempotency | Webhook Ordering Guarantees: When and How to Implement Them
Observability
Comprehensive observability across metrics, logs, and traces is essential. Each provides different insights needed to diagnose issues.
Track delivery success rate, latency percentiles (p50, p95, p99), retry rates, circuit breaker transitions, and queue depths—segmented by customer, endpoint, and webhook type. Alert on these to detect issues before customers notice.
Structured logs must include webhook ID, attempt number, URL, response status, response body, and timing. Distributed traces show how deliveries relate to original triggering events across service boundaries.
SLO Framework
Transform vague reliability goals into actionable targets:
| SLI (Service Level Indicator) | Target SLO | Alert Threshold |
|---|---|---|
| Delivery success rate | 99.9% | < 99.5% for 5 min |
| P95 delivery latency | < 5 seconds | > 10s for 5 min |
| Retry rate (% needing retry) | < 5% | > 10% for 15 min |
| DLQ rate (% undeliverable) | < 0.1% | > 0.5% for 1 hour |
Using this framework:
- Delivery success rate is your primary SLI—track per-customer and globally.
- P95 latency matters for time-sensitive webhooks (payments, real-time sync).
- Retry rate is an early warning—rising retries often precede failures.
- DLQ rate indicates systemic issues with endpoints or payloads.
Set alert thresholds tighter than SLO targets to respond before breaching. For example, alert at 99.5% if your SLO is 99.9%.
Deep dive: Webhook Observability: Logging, Metrics, and Distributed Tracing
Scaling Your Infrastructure
Webhook systems face unique scaling challenges: bursty traffic (single actions trigger dozens of endpoints), unpredictable external dependencies, and retry backlogs creating sudden load spikes hours later.
Scaling zero to thousands per second requires architectural decisions that are hard to change. Queue-based architectures decouple generation from delivery for independent scaling. Horizontal delivery worker scaling provides needed throughput. Database choices affect performance and operational complexity.
Understanding predictable growth phases helps you make appropriate investments—avoiding premature optimization and crippling technical debt.
Deep dive: Scaling Webhooks: From 0 to 10,000 Requests Per Second
Build vs Buy
Building in-house offers control and customization. Managed services let you focus on core product. The right choice depends on your circumstances.
Building's true cost extends beyond initial implementation: ongoing maintenance, on-call burden, scaling challenges, and engineering time opportunity costs. Many teams underestimate these, discovering their "simple" webhook system became a significant operational burden.
Consider your team's distributed systems expertise, reliability requirements, growth trajectory, and webhook delivery's strategic importance. For many, managed solutions provide enterprise reliability without engineering investment.
Deep dive: Build vs Buy: Webhook Infrastructure Decision Framework | The True Cost of Building Webhooks In-House
Production Defaults: Quick Reference
Consensus production defaults across major webhook providers:
| Parameter | Recommended Value | Notes |
|---|---|---|
| Initial retry delay | 5 seconds | Start aggressive for transient failures |
| Backoff multiplier | 5x exponential | Balance between scale and responsiveness |
| Maximum backoff cap | 6 hours | Prevents indefinitely long delays |
| Jitter | ±20% random | Prevents thundering herd on recovery |
| Maximum retry attempts | 15 total | Covers 72+ hour retry window |
| Total retry window | 72 hours | After which webhooks move to DLQ |
| Request timeout | 30 seconds | Stripe standard; consider customer latency |
| Circuit breaker threshold | 50% failure over 10-20 requests | Trip when 50%+ of recent requests fail |
| Circuit breaker cooldown | 60 seconds | Time before attempting half-open probe |
| Idempotency key retention | 24 hours minimum | Long enough to detect most duplicate delivery |
| Success rate SLO | 99.9% | Industry standard for reliability |
| Alert threshold | 99.5% success for 5 min | Alert before breaching SLO |
How to apply:
- For MVP: Use all defaults above (work for 99% of cases).
- For latency-sensitive webhooks (payments): Reduce timeout to 10-15s, increase retry aggressiveness.
- For non-critical webhooks (analytics): Increase backoff cap to 12h, reduce max attempts to 8.
- For high-volume systems (10k+ webhooks/sec): Reduce jitter to ±10%, consider batching.
Conclusion
Webhook reliability requires retry strategies, circuit breakers, idempotency, and observability. Each component is critical for infrastructure that delivers even when everything fails.
The patterns here represent hard-won lessons from scale. Implementing correctly requires significant engineering investment and ongoing attention.
For teams building in-house, this guide provides a roadmap. For teams focusing on core product, Hook Mesh provides enterprise-grade infrastructure with intelligent retries, circuit breakers, rate limiting, dead letter queues, idempotency, comprehensive observability, and horizontal scaling built-in.
Ready to stop worrying about webhook reliability? Start your free trial of Hook Mesh.